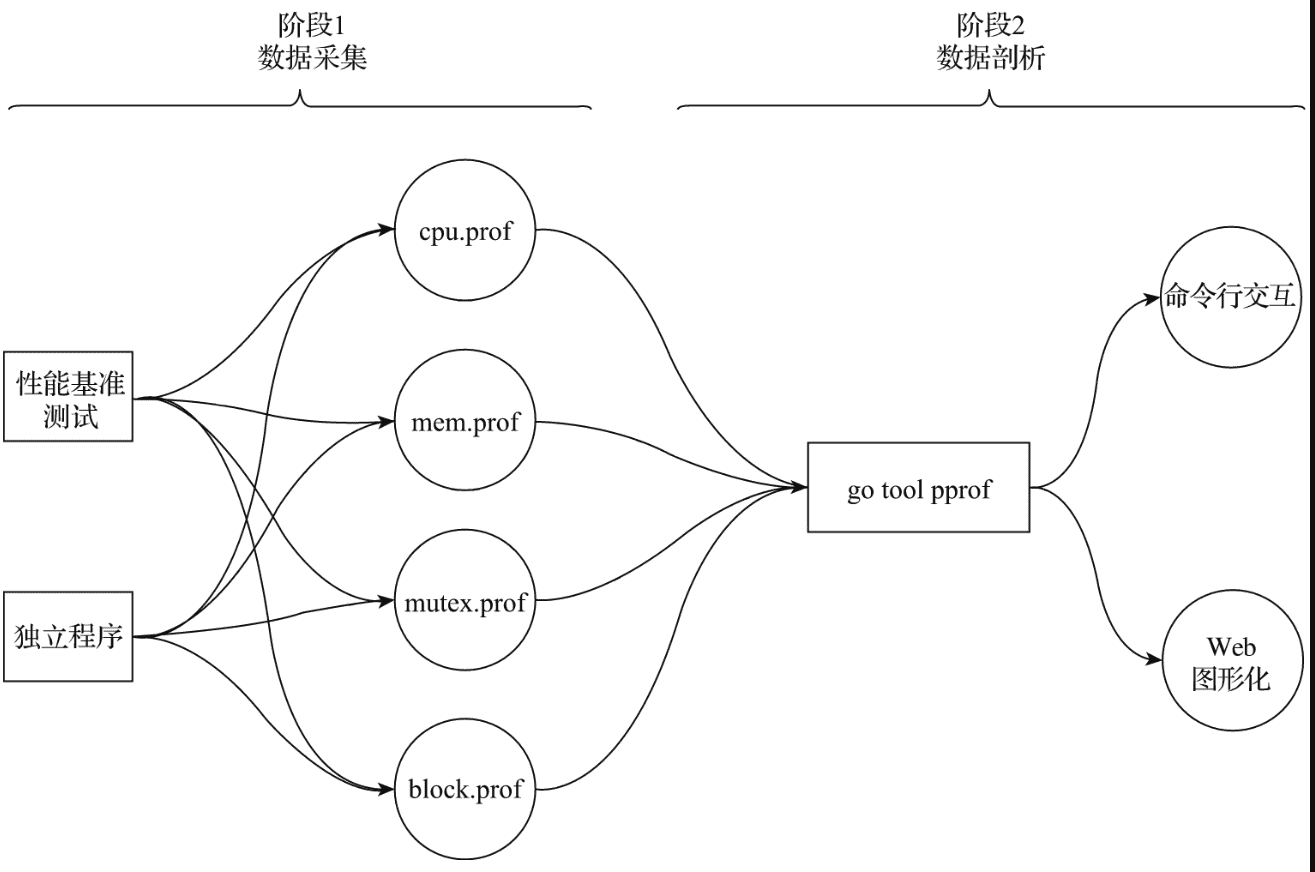
pprof工作原理 使用pprof进行性能剖析的工作一般分为两个阶段:数据采集和数据分析。
采样数据类型 在数据采集阶段,go运行时会定期对剖析阶段所需不同类型数据进行采样记录。当前主要支持的采样数据类型有如下几种。
cpu数据(对应cpu.prof) cpu 类型采样数据是性能剖析中十分常见的采样数据类型,它能帮助我们识别出代码关键路径上消耗cpu最多的函数。一旦启用cpu数据采样,go运行时会每隔一段短暂的时间(10ms)就中断一次(由SIGPROF信号引发)并记录当前所有goroutine的函数栈信息(存入cpu.prof)。
堆内存分配数据(对应mem.prof) 堆内存分配采样数据和CPU采样数据一样,也是性能剖析中十分常见的采样数据类型,它能帮助我们了解Go程序的当前和历史内存使用情况。堆内存分配的采样频率可配置,默认每1000次堆内存分配会做一次采样(存入mem.prof)。
锁竞争数据(对应mutex.prof) 锁竞争采样数据记录了当前Go程序中互斥锁争用导致延迟的操作。如果你认为很大可能是互斥锁争用导致CPU利用率不高,那么你可以为go tool pprof工具提供此类采样文件以供性能剖析阶段使用。该类型采样数据在默认情况下是不启用的,请参见runtime.SetMutexProfileFraction或go test -bench .xxx_test.go -mutexprofile mutex.out启用它。
阻塞时间数据(对应block.prof) 该类型采样数据记录的是goroutine在某共享资源(一般是由同步原语保护)上的阻塞时间,包括从无缓冲channel收发数据、阻塞在一个已经被其他goroutine锁住的互斥锁、向一个满了的channel发送数据或从一个空的channel接收数据等。该类型采样数据在默认情况下也是不启用的,请参见runtime.SetBlockProfileRate或go test -bench . xxx_test.go -blockprofile block.out启用它。
注意,采样不是免费的,因此一次采样尽量仅采样一种类型的数据,不要同时采样多种类型的数据,避免相互干扰采样结果。
性能数据采集的方式 Go目前主要支持两种性能数据采集方式:通过性能基准测试进行数据采集和独立程序的性能数据采集。
通过性能基准测试进行数据采集 为应用中的关键函数/方法建立起性能基准测试之后,我们便可以通过执行性能基准测试采集到整个测试执行过程中有关被测方法的各类性能数据。这种方式尤其适用于对应用中关键路径上关键函数/方法性能的剖析。
我们仅需为go test增加一些命令行选项即可在执行性能基准测试的同时进行性能数据采集。以CPU采样数据类型为例:
1 2 3 $ go test -bench . xxx_text.go -cpuprofile=cpu.prof ls prof xxx.text* xxx_text.go
一旦开启性能数据采集(比如传入-cpuprofile),go test的-c命令选项便会自动开启,go test命令执行后会自动编译出一个与该测试对应的可执行文件(这里是xxx.test)。该可执行文件可以在性能数据剖析过程中提供剖析所需的符号信息(如果没有该可执行文件,go tool pprof的disasm命令将无法给出对应符号的汇编代码)。而cpu.prof就是存储CPU性能采样数据的结果文件,后续将作为数据剖析过程的输入。
对于其他类型的采样数据,也可以采用同样的方法开启采集并设置输出文件:
1 2 3 $go test -bench . xxx_test.go -memprofile =mem.prof$go test -bench . xxx_test.go -blockprofile =block.prof$go test -bench . xxx_test.go -mutexprofile =mutex.prof
独立程序的性能数据采集 可以通过标准库runtime/pprof和runtime包提供的低级API对独立程序进行性能数据采集。下面是一个独立程序性能数据采集的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 package mainimport ("flag" "fmt" "log" "os" "os/signal" "runtime" "runtime/pprof" "sync" "syscall" "time" var cpuprofile = flag.String("cpuprofile" , "" , "write cpu profile to `file`" )var memprofile = flag.String("memprofile" , "" , "write mem profile to `file`" )var mutexprofile = flag.String("mutexprofile" , "" , "write mutex profile to `file`" )var blockprofile = flag.String("blockprofile" , "" , "write block profile to `file`" )func main () if *cpuprofile != "" {if err != nil {"could not create CPU profile: " , err)defer f.Close()if err := pprof.StartCPUProfile(f); err != nil {"counld not start CPU profile: " , err)defer pprof.StopCPUProfile()if *memprofile != "" {if err != nil {"cound not create MEM profile: " , err)defer f.Close()if err := pprof.WriteHeapProfile(f); err != nil {"could not write Heap profile: " , err)if *mutexprofile != "" {1 )defer runtime.SetMutexProfileFraction(0 )if err != nil {"could not create mutex profile: " , err)defer f.Close()if mp := pprof.Lookup("mutex" ); mp != nil {0 )if *blockprofile != "" {1 )defer runtime.SetBlockProfileRate(0 )if err != nil {"could not create block profile: " , err)defer f.Close()if mp := pprof.Lookup("mutex" ); mp != nil {0 )var wg sync.WaitGroupmake (chan os.Signal, 1 )1 )go func () for {select {case <-c:return default :"hello" "gopher" "!" 10 * time.Millisecond)"program exit" )
可以通过指定命令行参数的方式选择要采集的性能数据类型:
1 2 3 4 5 6 7 8 9 10 ~/Sites/go /src ❯ go run main.go --help 26 /3 kjb21h51d79f86q8hyfccx40000gn/T/go -build358720100/b001/exe /main:file write block profile to file file write cpu profile to file file write mem profile to file file write mutex profile to file
以 cpu 类型性能数据为例,执行下面的命令:
1 2 3 4 5 ~/Sites/g o/src ❯ go run main.go -cpuprofile cpu.profexit /Sites/g o/src ❯ ls -al cpu.prof 1 ezreal staff 809 8 19 18 :17 cpu.prof
程序退出后,我们在当前目录下看到采集后的 cpu 类型性能数据结果文件cpu.prof,该文件将被提供给go tool pprof工具用作后续剖析。
从上述示例我们看到,这种独立程序的性能数据采集方式对业务代码侵入较多,还要自己编写一些采集逻辑:定义flag变量、创建输出文件、关闭输出文件等。每次采集都要停止程序才能获取结果。(当然可以重新定义更复杂的控制采集时间窗口的逻辑,实现不停止程序也能获取采集数据结果。)
Go在net/http/pprof包中还提供了一种更为高级的针对独立程序的性能数据采集方式,这种方式尤其适合那些内置了HTTP服务的独立程序。net/http/pprof包可以直接利用已有的HTTP服务对外提供用于性能数据采集的服务端点(endpoint)。例如,一个已有的提供HTTP服务的独立程序代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package mainimport ("context" "fmt" "log" "net/http" "os" "os/signal" "syscall" func main () "/hello" , http.HandlerFunc(func (w http.ResponseWriter, r *http.Request) byte ("hello" ))"localhost:808" ,make (chan os.Signal, 1 )go func ()
如果要采集该HTTP服务的性能数据,我们仅需在该独立程序的代码中像下面这样导入net/http/pprof包即可:
1 2 3 import (_ "net/http/pprof"
下面是net/http/pprof包的init函数,这就是空导入net/http/pprof的“副作用”:
1 2 3 4 5 6 7 func init () "/debug/pprof/" , Index) "/debug/pprof/cmdline" , Cmdline) "/debug/pprof/profile" , Profile) "/debug/pprof/symbol" , Symbol) "/debug/pprof/trace" , Trace)
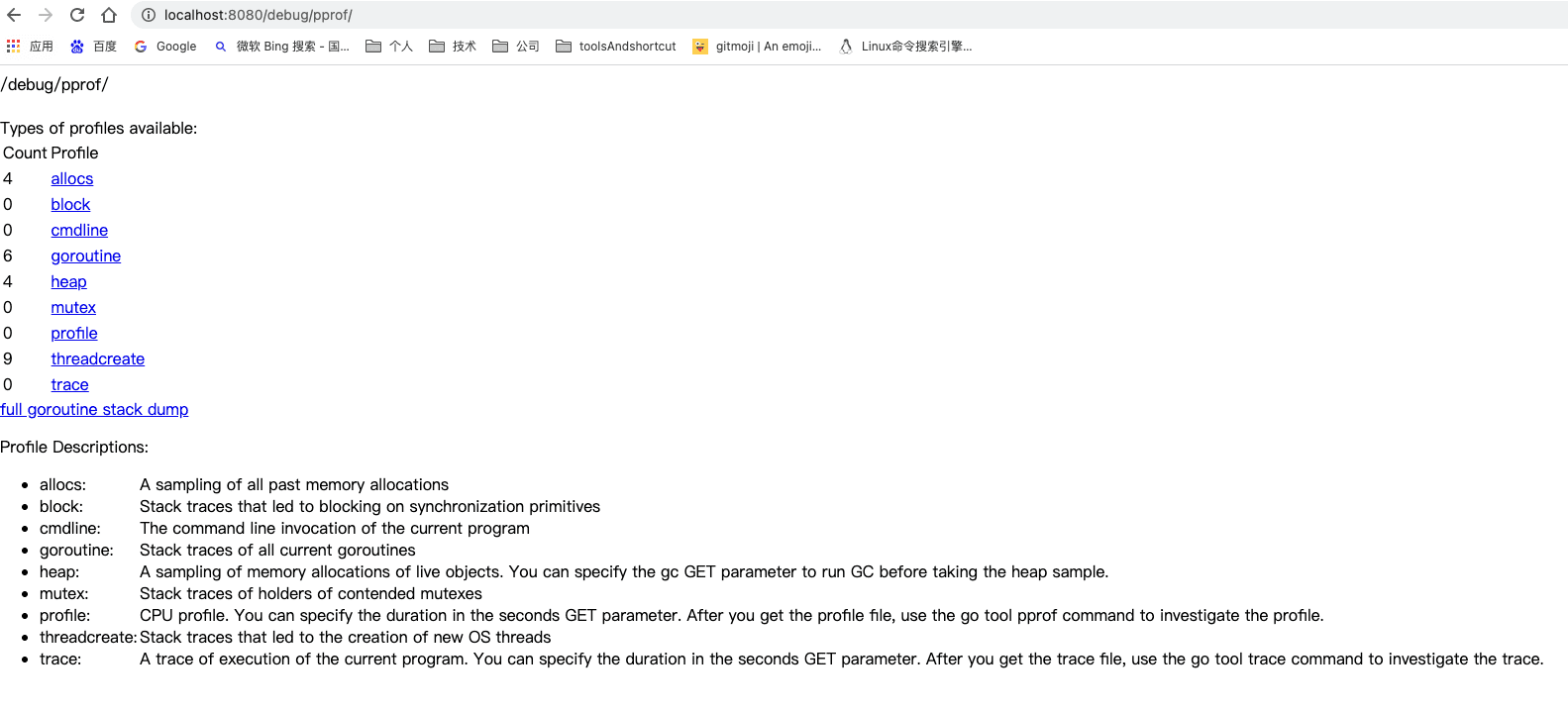
我们看到该包的init函数向http包的默认请求路由器DefaultServeMux注册了多个服务端点和对应的处理函数。而正是通过这些服务端点,我们可以在该独立程序运行期间获取各种类型的性能采集数据。现在打开浏览器,访问http://localhost:8080/debug/pprof/,我们就可以看到下图所示的页面。
这个页面里列出了多种类型的性能采集数据,点击其中任何一个即可完成该种类型性能数据的一次采集。profile是CPU类型数据的服务端点,点击该端点后,该服务默认会发起一次持续30秒的性能采集,得到的数据文件会由浏览器自动下载到本地。如果想自定义采集时长,可以通过为服务端点传递时长参数实现,比如下面就是一个采样60秒的请求:
1 http://localhost:8080 /debug /pprof/profile ?seconds=60
如果独立程序的代码中没有使用http包的默认请求路由器DefaultServeMux,那么我们就需要重新在新的路由器上为pprof包提供的性能数据采集方法注册服务端点,就像下面的示例一样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 func main () "/debug/pprof/" , pprof.Index) "/debug/pprof/profile" , pprof.Profile) "/hello" , http.HandlerFunc(func (w http.ResponseWriter, r *http.Request) byte ("hello" )) "localhost:8080" , make (chan os.Signal, 1 ) go func ()
如果是非HTTP服务程序,则在导入包的同时还需单独启动一个用于性能数据采集的goroutine,像下面这样:
1 2 3 4 5 6 7 func main () go func () "localhost:8080" , nil ))
通过上面几个示例我们可以看出,相比第一种方式,导入net/http/pprof包进行独立程序性能数据采集的方式侵入性更小,代码也更为独立,并且无须停止程序,通过预置好的各类性能数据采集服务端点即可随时进行性能数据采集。
性能数据的剖析 Go工具链通过pprof子命令提供了两种性能数据剖析方法:命令行交互式和Web图形化。命令行交互式的剖析方法更常用,也是基本的性能数据剖析方法;而基于Web图形化的剖析方法在剖析结果展示上更为直观。
命令行交互的方式 可以通过下面三种方式执行go tool pprof以进入采用命令行交互式的性能数据剖析环节:
1 2 3 $go tool pprof xxx.test cpu.prof // 剖析通过性能基准测试采集的数据$go tool pprof standalone_app cpu.prof // 剖析独立程序输出的性能采集数据// 通过net/http/ pprof注册的性能采集数据服务端点获取数据并剖析$go tool pprof http:// localhost:8080 /debug/ pprof/profile
以上文生成的cpu.prof 文件为例,通过go tool pprof 命令进入命令行交互模式:
1 2 3 4 5 6 ~/Sites/go/src/pprof/runtime ❯ go tool pprof cpu.profTime: Aug 22, 2022 at 11:27am (CST)
从pprof子命令的输出中我们看到:程序运行28.61s,采样总时间为180ms,占总时间的0.63%。
命令行交互方式下最常用的命令是topN(N为数字,如果不指定,默认等于10):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 (pprof) top180 ms, 100 10 nodes out of 18 70 ms 38.89 60 ms 33.33 20 ms 11.11 20 ms 11.11 10 ms 5.56 0 0 0 0 0 0 0 0 0 0
topN命令的输出结果默认按flat(flat%)从大到小的顺序输出。
列名
含义
flat
flat列的值表示函数自身代码在数据采样过程中的执行时长。
flat%
flat%列的值表示函数自身代码在数据采样过程中的执行时长占总采样执行时长的百分比。
sum%
sum%列的值是当前行flat%值与排在该值前面所有行的flat%值的累加和。以第三行的sum%值83.33%为例,该值由前三行flat%累加而得,即38.89% + 33.33% + 11.11% = 83.33%。
cum
cum列的值表示函数自身在数据采样过程中出现的时长,这个时长是其自身代码执行时长及其等待其调用的函数返回所用时长的总和。越是接近函数调用栈底层的代码,其cum列的值越大。(也就是该函数加上该函数调用的函数总耗时)
cum%
cum%列的值表示该函数cum值占总采样时长的百分比。比如:runtime.findrunnable函数的cum值为160ms,总采样时长为180ms,则其cum%值为两者的比值百分化后的值。
命令行交互模式也支持按cum值从大到小的顺序输出采样结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 (pprof) top -cum160 ms, 88.89 10 nodes out of 18 0 0 0 0 0 0 0 0 10 ms 5.56 70 ms 38.89 60 ms 33.33 0 0 0 0 20 ms 11.11
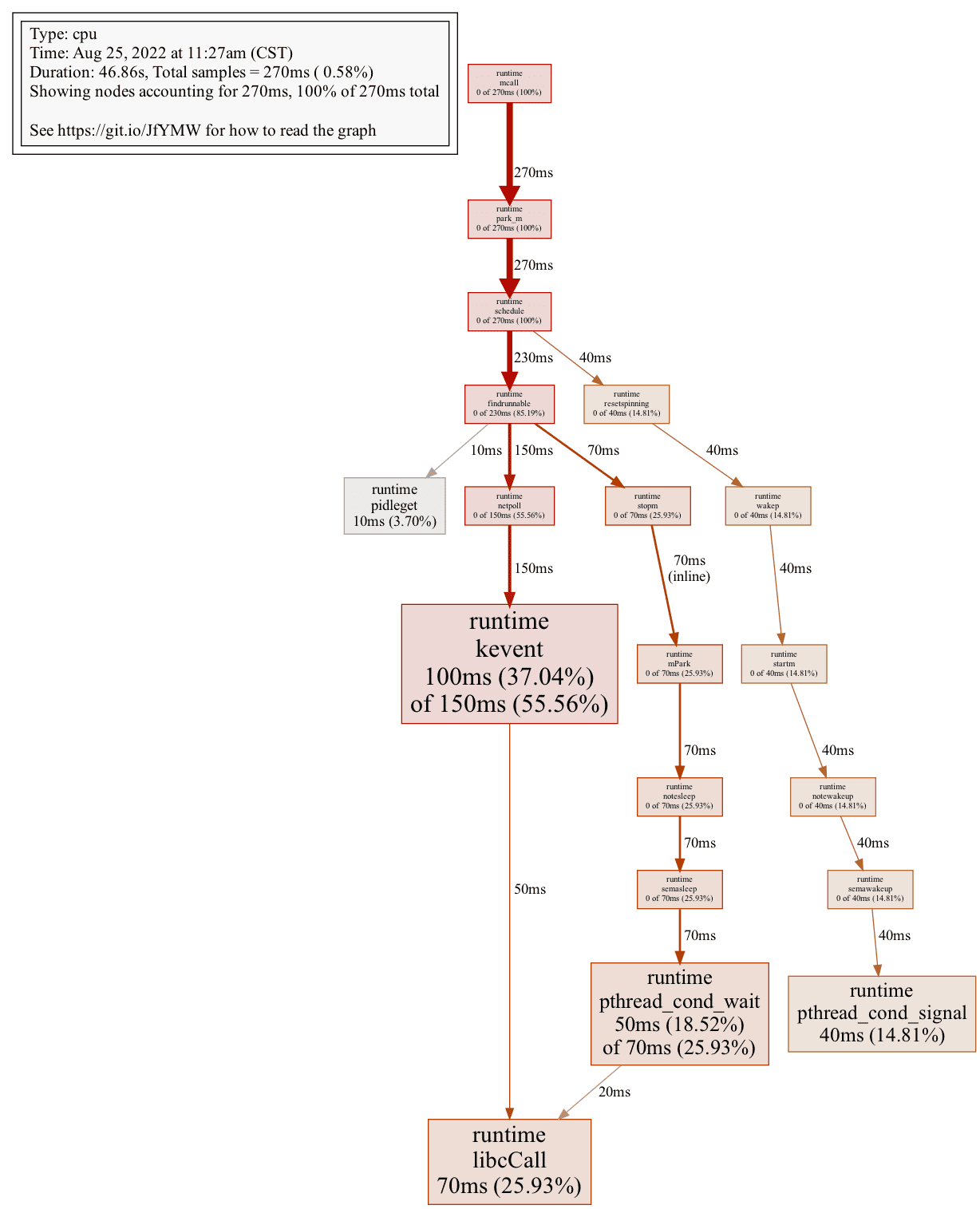
在命令行交互模式下,还可以生成CPU采样数据的函数调用图,且可以导出为多种格式,如PDF、PNG、JPG、GIF、SVG等。不过要做到这一点,前提是本地已安装图片生成所依赖的插件graphviz。
如下导出一副png格式的图片:
1 2 3 (pprof) pngGenerating report in profile001.png
png命令会在当前目录下生成一张名为profile001.png的图片文件:
在图片中,我们可以清晰地看到cum%较大的叶子节点(用黑色粗体标出,叶子节点的cum%值与flat%值相等),它们就是我们需要重点关注的优化点。
在命令行交互模式下,通过web命令还可以在输出SVG格式图片的同时自动打开本地浏览器展示该图片。要实现这个功能也有一个前提,那就是本地SVG文件的默认打开应用为浏览器,否则生成的SVG文件很可能会以其他文本形式被其他应用打开。
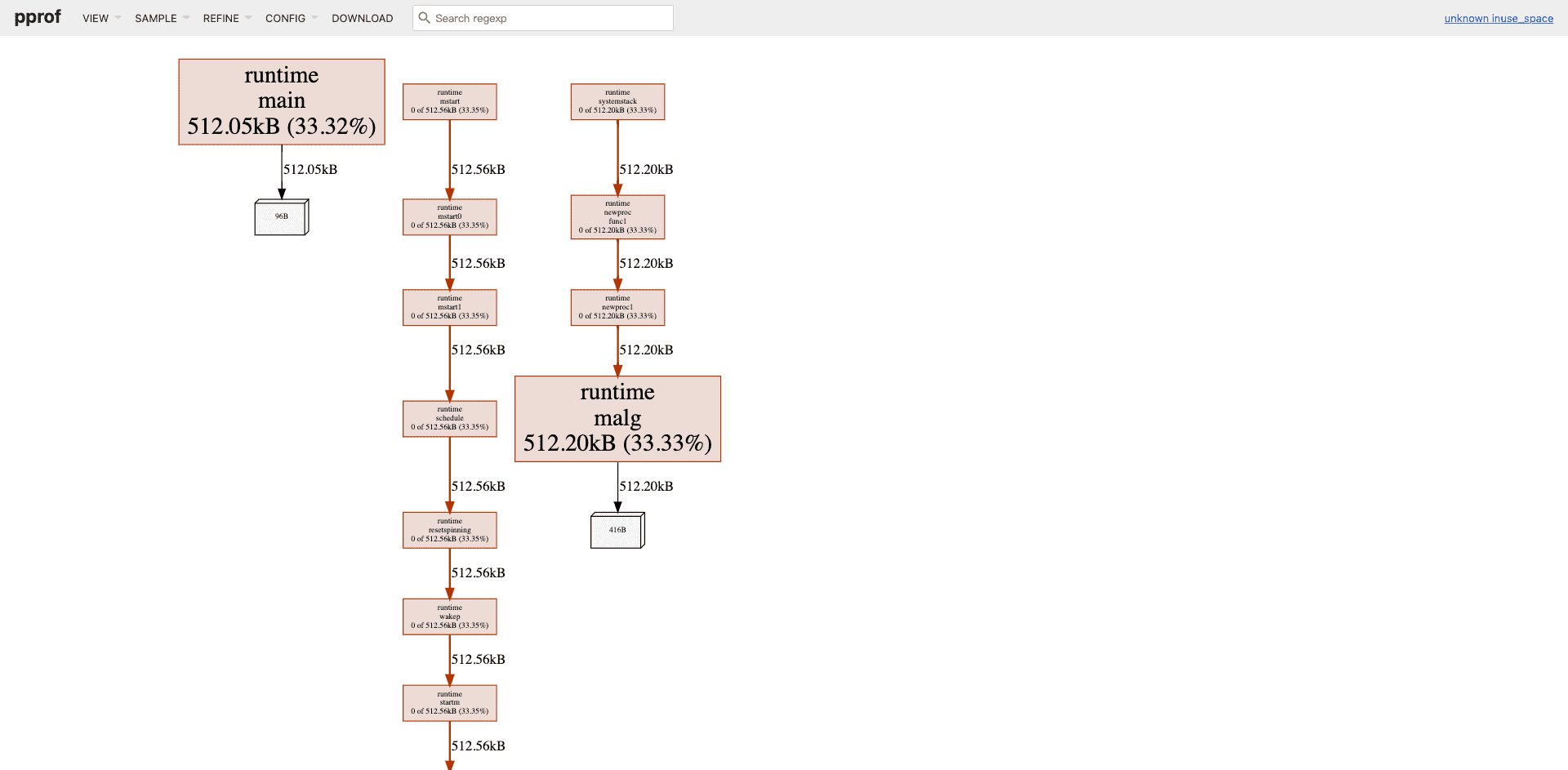
Web图形化方式 对于喜好通过图形化交互(GUI)方式剖析程序性能的开发者,go tool pprof提供了基于Web的图形化呈现所采集性能数据的方式。对于已经生成好的各类性能采集数据文件,我们可以通过下面的命令行启动一个Web服务并自动打开本地浏览器、进入图形化剖析页面:
1 2 ~/Sites/go /src/pprof/runtime 5 m 18 s ❯ go tool pprof --http=:9999 mem.prof on http://localhost:9999
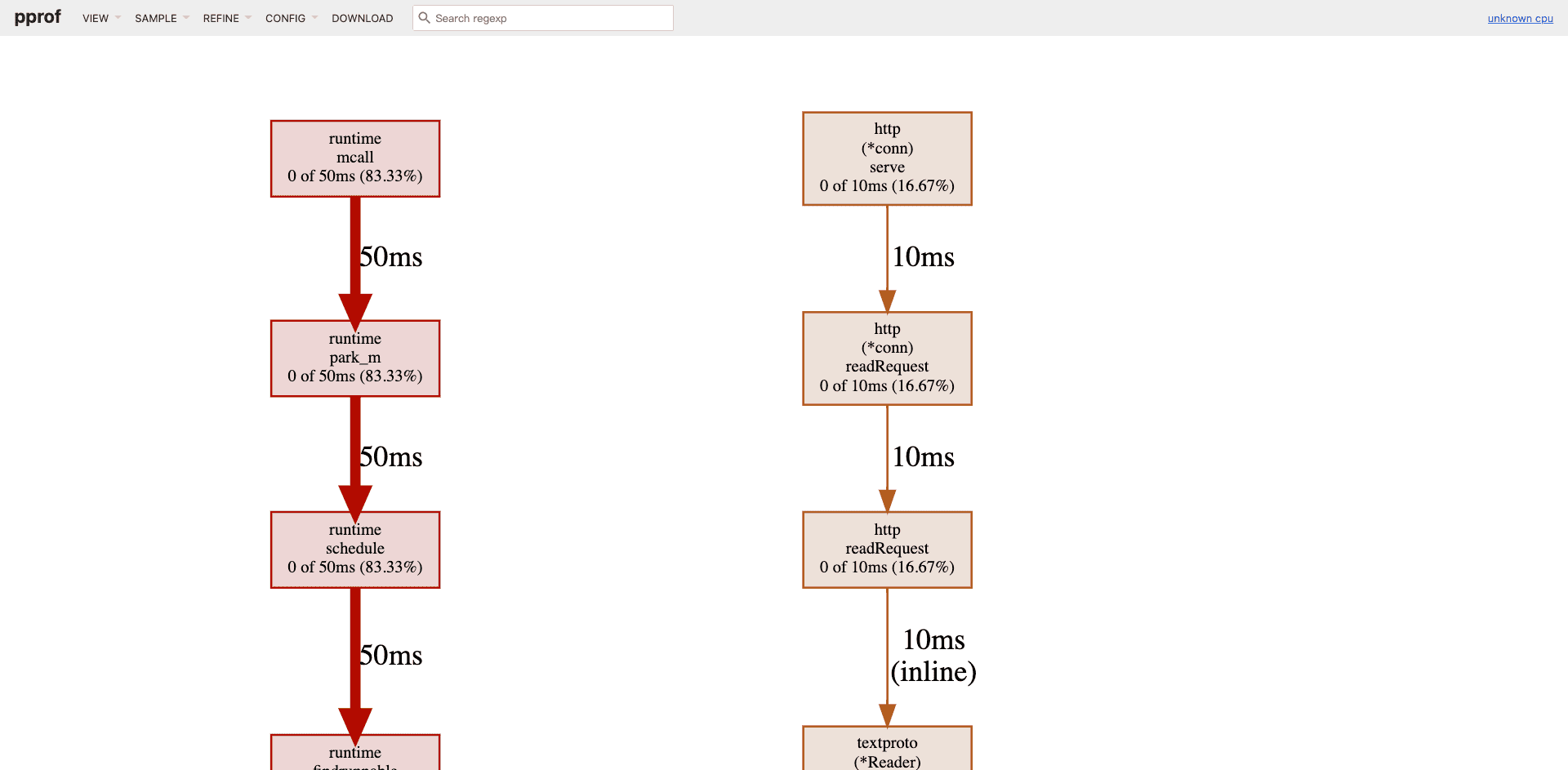
图形化剖析页面的默认视图(VIEW)是Graph,即函数调用图。在图47-4左上角的VIEW下拉菜单中,还可以看到Top、Source、Flame Graph等菜单项。
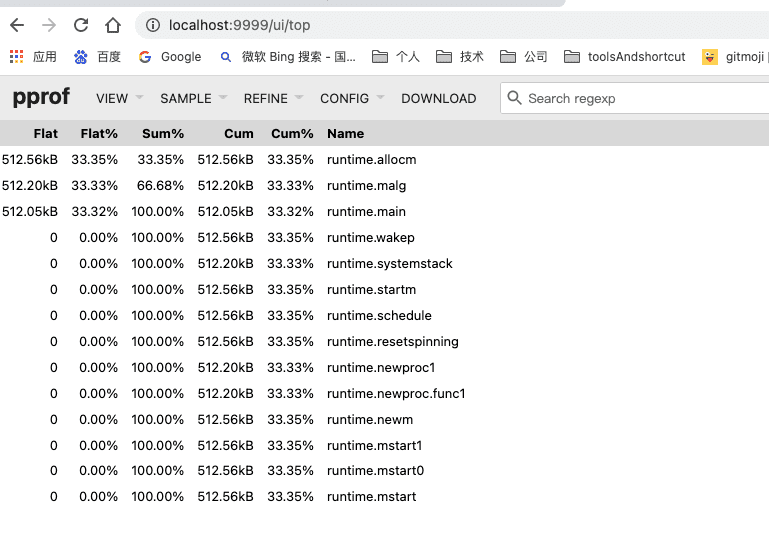
Top视图等价于命令行交互模式下的topN命令输出:
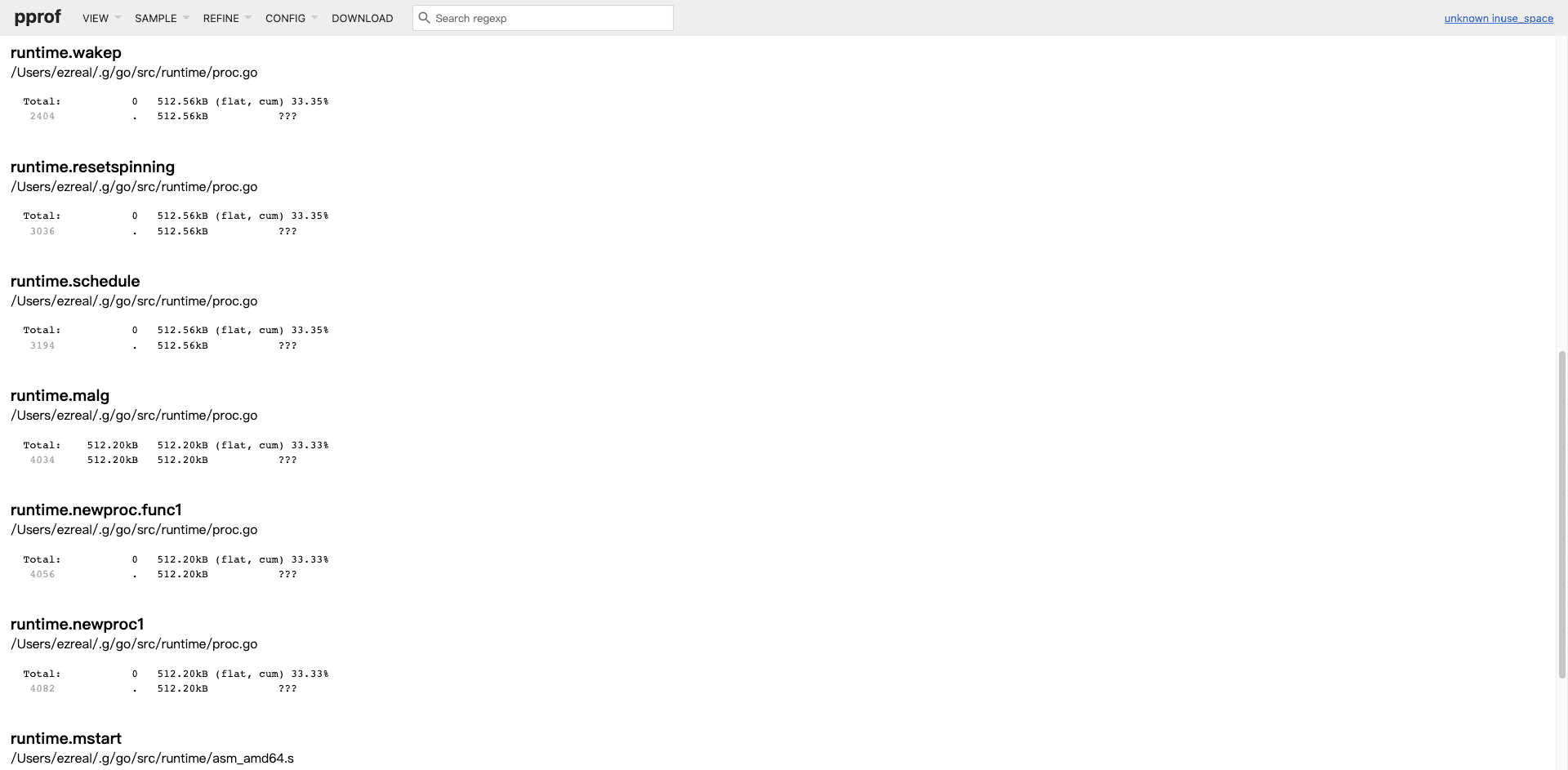
Source视图等价于命令行交互模式下的list命令输出,只是这里将所有采样到的函数相关源码全部在一个页面列出了。
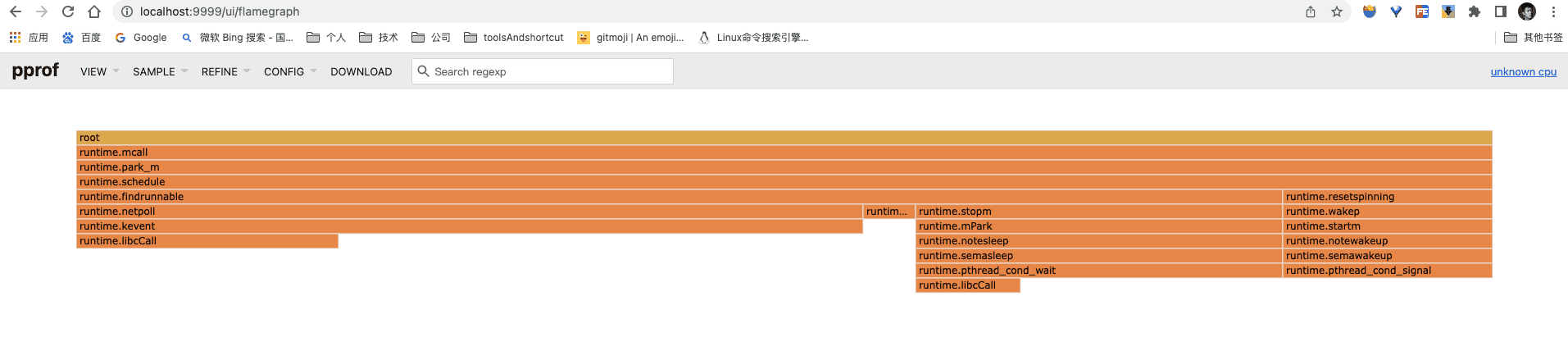
Flame Graph视图即火焰图,该类型视图由性能架构师Brendan Gregg发明,并在近几年被广大开发人员接受。Go 1.10版本在go工具链中添加了对火焰图的支持。通过火焰图,我们可以快速、准确地识别出执行最频繁的代码路径,因此它多用于对CPU类型采集数据的辅助剖析(其他类型的性能采样数据也有对应的火焰图,比如内存分配)。
go tool pprof在浏览器中呈现出的火焰图与标准火焰图有些差异:它是倒置的,即调用栈最顶端的函数在最下方。在这样一幅倒置火焰图中,y轴表示函数调用栈,每一层都是一个函数。调用栈越深,火焰越高。倒置火焰图每个函数调用栈的最下方就是正在执行的函数,上方都是它的父函数。
火焰图的x轴表示抽样数量,如果一个函数在x轴上占据的宽度越宽,就表示它被抽样到的次数越多,即执行的时间越长。倒置火焰图就是看最下面的哪个函数占据的宽度最大,这样的函数可能存在性能问题。
当鼠标悬浮在火焰图中的任意一个函数上时,图上方会显示该函数的性能采样详细信息。在火焰图中任意点击某个函数栈上的函数,火焰图都会水平局部放大,该函数会占据所在层的全部宽度,显示更为详细的信息。再点击root层或REFINE下拉菜单中的Reset可恢复火焰图原来的样子。
对于通过net/http/pprof暴露性能数据采样端点的独立程序,同样可以采用基于Web的图形化页面进行性能剖析。以pprof_standalone4.go的剖析为例:
1 2 3 4 5 6 7 8 // 启动程序go /src/pprof/net ❯ go run main.go go /src/pprof/net 1 m 4 s ❯ go tool pprof --http=:9999 http://localhost:8080 /debug /pprof/profile profile over HTTP from http://localhost:8080 /debug /pprof/profile profile in /Users/ezreal/pprof/pprof.samples.cpu.002 .pb.gzon http://localhost:9999
执行go tool pprof时,pprof会对main.go进行默认30秒的CPU类型性能数据采样,然后将采集的数据下载到本地,存为pprof.samples.cpu.001.pb.gz,之后go tool pprof加载pprof.samples.cpu.001.pb.gz并自动启动浏览器进入性能剖析默认页面(函数调用图),如图所示。
使用pprof进行性能剖析的实例 前面我们了解了go tool pprof的工作原理、性能数据类别、采样方式及剖析方式等,下面用一个实例来整体说明利用pprof进行性能剖析的过程。该示例改编自Brad Fitzpatrick在YAPC Asia 2015 上的一次名为“Go Debugging, Profiling, and Optimization”的技术分享。
待优化程序 待优化程序是一个简单的HTTP服务,当通过浏览器访问其/hi服务端点时,页面上会显示如下图所示的内容。
页面上有一个计数器,显示访客是网站的第几个访客。该页面还支持通过color参数进行标题颜色定制,比如使用浏览器访问下面的地址后,页面显示的“Welcome!”标题将变成红色。
1 http://localhost:8080 /hi ?color=red
该待优化程序的源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 package mainimport ("fmt" "log" "net/http" "regexp" "sync/atomic" var visitors int64 func handleHi (w http.ResponseWriter, r *http.Request) if match, _ := regexp.MatchString(`^\w*$` , r.FormValue("color" )); !match {"Optional color is invalid" , http.StatusBadRequest)return 1 )"Content-Type" , "text/html; charset=utf-8" )byte ("<h1 style='color: " + r.FormValue("color" ) + "'>Welcome!</h1>You are visitor number " + fmt.Sprint(visitNum) + "!" ))func main () "Starting on port 8080" )"/hi" , handleHi)"127.0.0.1:8080" , nil ))
这里,我们实验的环境为go version go1.18.3 darwin/amd64
CPU类性能数据采样及数据剖析 前面提到go tool pprof支持多种类型的性能数据采集和剖析,在大多数情况下我们都会先从CPU类性能数据的剖析开始。这里通过为示例程序建立性能基准测试的方式采集CPU类性能数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mainimport ("bufio" "net/http" "net/http/httptest" "strings" "testing" func BenchmarkHi (b *testing.B) "GET /hi HTTP1.0\r\n\r\n" )))if err != nil {for i := 0 ; i < b.N; i++ {
建立基准,取得初始基准测试数据:
1 2 3 4 5 6 7 8 9 ~/Sites/go/ src/pprof/ sample ❯ go test -v -bench = . -run = ^$goos: darwingoarch: amd64pkg: ezreal/pprof/ samplecpu: Intel(R) Core(TM) i5-8257 U CPU @ 1.40 GHz-8 361098 3155 ns/op/pprof/ sample 2.513 s
接下来,利用基准测试采样CPU类型性能数据:
1 2 3 4 5 6 7 8 9 10 11 12 ~/Sites/go/ src/pprof/ sample ❯ go test -v -bench = . -run = ^BenchmarkHi$ -benchtime = 2 s -cpuprofile = cpu.profgoos: darwingoarch: amd64pkg: ezreal/pprof/ samplecpu: Intel(R) Core(TM) i5-8257 U CPU @ 1.40 GHz-8 741999 3137 ns/op/pprof/ sample 5.023 s/go/ src/pprof/ sample 5 s ❯ ls
执行完成后,当前目录下会出现两个新文件cpu.prof和sample.test。我们将这两个文件作为go tool pprof的输入对性能进行剖析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ~/Sites/go/src/pprof/sample 19 s ❯ go tool pprof sample.test cpu.prof26 , 2022 at 10 :39 am (CST)4.44 s, Total samples = 3.81 s (85.89 type "help" for commands, "o" for options)for 0.56 s, 14.70 71 nodes (cum <= 0.02 s)10 nodes out of 140 0 0 0.01 s 0.26 0 0 0 0 0 0 0 0 0.03 s 0.79 0.51 s 13.39 0 0 0.01 s 0.26
通过top -cum,我们看到handleHi累积消耗CPU最多(用户层代码范畴)。通过list命令进一步展开handleHi函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 (pprof) list handleHi3.81s 10ms 2.80s (flat, cum) 73.49% of Total9 :)10 :11 :var visitors int6412 :13 :func handleHi (w http.ResponseWriter, r *http.Request) {2.31s 14 : if match, _ := regexp.MatchString (`^\w*$`, r.FormValue ("color" )); !match {15 : http.Error (w, "Optional color is invalid" , http.StatusBadRequest)16 : return17 : }10ms 10ms 18 : visitNum := atomic.AddInt64 (&visitors, 1 )100ms 19 : w.Header ().Set ("Content-Type" , "text/html; charset=utf-8" )380ms 20 : w.Write ([]byte ("<h1 style='color: " + r.FormValue ("color" ) + "'>Welcome!</h1>You are visitor number " + fmt.Sprint (visitNum) + "!" ))21 :}22 :23 :func main () {24 : log.Printf ("Starting on port 8080" )25 : http.HandleFunc ("/hi" , handleHi)
我们看到在handleHi中,MatchString函数调用耗时最长(2.31s)。
第一次优化 通过前面对CPU类性能数据的剖析,我们发现MatchString较为耗时。通过阅读代码发现,每次HTTP服务接收请求后,都会采用正则表达式对请求中的color参数值做一次匹配校验。校验使用的是regexp包的MatchString函数,该函数每次执行都要重新编译传入的正则表达式,因此速度较慢。我们的优化手段是:让正则表达式仅编译一次。下面是优化后的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 ...var rxOptionalID = regexp.MustCompile (`^\w*$`)handleHi (w http.ResponseWriter , r *http.Request) {if !rxOptionalID.MatchString (r.FormValue ("coloe" )) {.Error (w, "Optional color is invalid" , http.StatusBadRequest).AddInt64 (&visitors, 1 ).Header ().Set ("Content-Type" , "text/html; charset=utf-8" ).Write ([] byte ("<h1 style='color: " + r.FormValue ("color" ) + "'>Welcome!</h1>You are visitor number " + fmt.Sprint (visitNum) + "!" ))
在优化后的代码中,我们使用一个代表编译后正则表达式对象的rxOptionalID的MatchString方法替换掉了每次都需要重新编译正则表达式的MatchString函数调用。
重新运行一下性能基准测试:
1 2 3 4 5 6 7 8 9 ~/Sites/go/ src/pprof/ sample 39 m 8 s ❯ go test -v -bench = . -run = ^$goos: darwingoarch: amd64pkg: ezreal/pprof/ samplecpu: Intel(R) Core(TM) i5-8257 U CPU @ 1.40 GHz-8 2678142 448.2 ns/op/pprof/ sample 2.297 s
相比于优化前(3155 ns/op),优化后handleHi的性能(448.2 ns/op)提高了7倍多。
内存分配采样数据分析 在对待优化程序完成CPU类型性能数据剖析及优化实施之后,再来采集另一种常用的性能采样数据——内存分配类型数据,探索一下在内存分配方面是否还有优化空间。Go程序内存分配一旦过频过多,就会大幅增加Go GC的工作负荷,这不仅会增加GC所使用的CPU开销,还会导致GC延迟增大,从而影响应用的整体性能。因此,优化内存分配行为在一定程度上也是提升应用程序性能的手段。
在压测代码中的BenchmarkHi函数中添加Report-Allocs方法调用,让其输出内存分配信息。然后,通过性能基准测试的执行获取内存分配采样数据:
代码修改:
1 2 3 4 5 6 7 8 9 10 11 12 ....b *testing.B ) {b .ReportAllocs ()ReadRequest (bufio.NewReader (strings.NewReader ("GET /hi HTTP/1.0\r\n\r\n" )))b .Fatal (err)NewRecorder ()0 ; i < b .N ; i ++ {
压测:
1 2 3 4 5 6 7 8 9 ~/Sites/go/ src/pprof/ sample 16 s ❯ go test -v -bench = . -run = ^BenchmarkHi$ -benchtime = 2 s -memprofile = mem.profgoos: darwingoarch: amd64pkg: ezreal/pprof/ samplecpu: Intel(R) Core(TM) i5-8257 U CPU @ 1.40 GHz-8 5389849 454.6 ns/op 359 B/op 5 allocs/op/pprof/ sample 3.528 s
接下来,使用pprof工具剖析输出内存分配采用数据(mem.prof):
1 2 3 4 5 6 ~/Sites/go/src/pprof/sample ❯ go tool pprof sample .test mem.profFile : sample .test Type : alloc_spacetype "help" for commands, "o" for options)
在go tool pprof的输出中有一行为Type:alloc_space。这行的含义是当前pprof将呈现程序运行期间所有内存分配的采样数据(即使该分配的内存在最后一次采样时已经被释放)。还可以让pprof将Type切换为inuse_space,这个类型表示内存数据采样结束时依然在用的内存。
可以在启动pprof工具时指定所使用的内存数据呈现类型:
1 2 $go tool pprof --alloc_space sample.test mem.prof $go tool pprof -sample_index=alloc_space sample.test mem.prof
亦可在进入pprof交互模式后,通过sample_index命令实现切换:
1 (pprof) sample_index = inuse_space
现在以alloc_space类型进入pprof命令交互界面并执行top命令:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ~/Sites/go/src/pprof/sample ❯ go tool pprof -sample_index=alloc_space sample .test mem.profFile : sample .test Type : alloc_spacetype "help" for commands, "o" for options)for 2149.27MB, 99.79% of 2153.79MB total out of 11sum % cum cum%sample .handleHinet /textproto.MIMEHeader.Set (inline)sample .BenchmarkHinet /http.Header.Set (inline)net /http/httptest.(*ResponseRecorder).Write
我们看到handleHi分配了较多内存。通过list命令展开handleHi的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 (pprof) list handleHi2.10 GB832.05 MB 2.10 GB (flat, cum) 99.81% of Total11 :var visitors int6412 :13 :var rxOptionalID = regexp.MustCompile (`^\w*$`)14 :15 :func handleHi (w http.ResponseWriter, r *http.Request) {512 kB 16 : if !rxOptionalID.MatchString (r.FormValue ("coloe" )) {17 : http.Error (w, "Optional color is invalid" , http.StatusBadRequest)18 : return19 : }20 : visitNum := atomic.AddInt64 (&visitors, 1 )97.50 MB 21 : w.Header ().Set ("Content-Type" , "text/html; charset=utf-8" )832.05 MB 2 GB 22 : w.Write ([]byte ("<h1 style='color: " + r.FormValue ("color" ) + "'>Welcome!</h1>You are visitor number " + fmt.Sprint (visitNum) + "!" ))23 :}24 :25 :func main () {26 : log.Printf ("Starting on port 8080" )27 : http.HandleFunc ("/hi" , handleHi)
通过list的输出结果我们可以看到handleHi函数的第22行分配了较多内存(见第一列)。
第二次优化 这里进行内存分配的优化方法如下:
删除w.Header().Set这行调用
使用fmt.Fprintf替代w.Write。
优化后的handleHi代码如下:
1 2 3 4 5 6 7 8 9 10 ...handleHi (w http.ResponseWriter , r *http.Request) {if !rxOptionalID.MatchString (r.FormValue ("coloe" )) {.Error (w, "Optional color is invalid" , http.StatusBadRequest).AddInt64 (&visitors, 1 ).Fprintf (w, "<h1 style='color: %s'>Welcome!</h1>You are visitor number %d!" , r.FormValue ("color" ), visitNum)
再次执行性能基准测试来搜集内存采样数据:
1 2 3 4 5 6 7 8 9 ~/Sites/go/ src/pprof/ sample 6 m 17 s ❯ go test -v -bench = . -run = ^BenchmarkHi$ -benchtime = 2 s -memprofile = mem.profgoos: darwingoarch: amd64pkg: ezreal/pprof/ samplecpu: Intel(R) Core(TM) i5-8257 U CPU @ 1.40 GHz-8 7754635 304.1 ns/op 146 B/op 1 allocs/op/pprof/ sample 3.264 s
和优化前的数据对比,内存分配次数由5allocs/op降为1 allocs/op,每op分配的字节数由359B降为146B。
再次通过pprof对上面的内存采样数据进行分析,查看BenchmarkHi中的内存分配情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 ~/Sites/go/src/pprof/sample ❯ go tool pprof -sample_index=alloc_space sample .test mem.profFile : sample .test Type : alloc_spacetype "help" for commands, "o" for options)for 1211.33MB, 99.71% of 1214.83MB total sum % cum cum%sample .handleHisample .BenchmarkHinet /http/httptest.(*ResponseRecorder).Writelist handleHiTotal : 1.19GBsample .handleHi in /Users/ezreal/Sites/go/src/pprof/sample /main.goTotal return "<h1 style='color: %s'>Welcome!</h1>You are visitor number %d!" , r.FormValue("color" ), visitNum)log .Printf("Starting on port 8080" )"/hi" , handleHi)
我们看到,对比优化前handleHi的内存分配的确大幅减少(第一列:832.05MB ->58MB)。
零内存分配 经过一轮内存优化后,handleHi当前的内存分配集中到下面这行代码:
1 fmt.Fprintf(w, "<html > <h1 stype ='color: %s' > Welcome!</h1 > You are visitor number %d!", r.FormValue("color"), visitNum)
fmt.Fprint的原型如下:
1 2 3 4 5 6 ~/Sites/go/src/pprof/sample 7 m 2 s ❯ go doc fmt.Fprintfformat string , a ...any ) (n int, err error)to a format specifier and writes to w. It returnsthe number of bytes written and any write error encountered.
我们看到Fprintf参数列表中的变长参数都是interface{}类型。一个接口类型占据两个字(word),在64位架构下,这两个字就是16字节。这意味着我们每次调用fmt.Fprintf,程序就要为每个变参分配一个占用16字节的接口类型变量,然后用传入的类型初始化该接口类型变量。这就是这行代码分配内存较多的原因。
要实现零内存分配,可以像下面这样优化代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ....var visitors int64 var rxOptionalID = regexp.MustCompile(`^\w*$` )var bufPool = sync.Pool{func () interface {} {return bytes.NewBuffer(make ([]byte , 128 ))func handleHi (w http.ResponseWriter, r *http.Request) if !rxOptionalID.MatchString(r.FormValue("coloe" )) {"Optional color is invalid" , http.StatusBadRequest)return 1 )defer bufPool.Put(buf)"<h1 style='color: " )"color" ))"'>Welcome!</h1>You are visitor number " )10 )append (b, '!' )
这里有几点主要优化:
使用sync.Pool减少重新分配bytes.Buffer的次数;采用预分配底层存储的bytes.Buffer拼接输出;使用strconv.AppendInt将整型数拼接到bytes.Buffer中,strconv.AppendInt的实现如下:
1 2 3 4 5 6 7 8 func AppendInt (dst []byte , i int64 , base int ) byte { if fastSmalls && 0 <= i && i < nSmalls && base == 10 { return append (dst, small(int (i))...) uint64 (i), base, i < 0 , true ) return dst
我们看到AppendInt内置对十进制数的优化。对于我们的代码而言,这个优化的结果就是没有新分配内存,而是利用了传入的bytes.Buffer的实例,这样,代码中strconv.AppendInt的返回值变量b就是bytes.Buffer实例的底层存储切片。
运行一下最新优化后代码的性能基准测试并采样内存分配性能数据:
1 2 3 4 5 6 7 8 9 ~/Sites/go/ src/pprof/ sample ❯ go test -v -bench = . -run = ^BenchmarkHi$ -benchtime = 2 s -memprofile = mem.profgoos: darwingoarch: amd64pkg: ezreal/pprof/ samplecpu: Intel(R) Core(TM) i5-8257 U CPU @ 1.40 GHz-8 13095064 200.0 ns/op 163 B/op 0 allocs/op/pprof/ sample 3.002 s
可以看到,上述性能基准测试的输出结果中每op的内存分配次数为0,而且程序性能也有了提升(304.1 ns/op → 200 ns/op)。剖析一下输出的内存采样数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 ~/Sites/go/src/pprof/sample ❯ go tool pprof -sample_index=alloc_space sample .test mem.profFile : sample .test Type : alloc_spacetype "help" for commands, "o" for options)for 2.12GB, 99.84% of 2.13GB total sum % cum cum%sample .BenchmarkHisample .handleHinet /http/httptest.(*ResponseRecorder).Writelist handleHiTotal : 2.13GBsample .handleHi in /Users/ezreal/Sites/go/src/pprof/sample /main.goTotal "<h1 style='color: " )"color" ))"'>Welcome!</h1>You are visitor number " )append (b, '!')log .Printf("Starting on port 8080" )"/hi" , handleHi)log .Fatal(http.ListenAndServe("127.0.0.1:8080" , nil))
从handleHi代码展开的结果中已经看不到内存分配的数据了(第一列)。
查看并发下的阻塞情况 前面进行的性能基准测试都是顺序执行的,无法反映出handleHi在并发下多个goroutine的阻塞情况,比如在某个处理环节等待时间过长等。为了了解并发下handleHi的表现,我们为它编写了一个并发性能基准测试:
1 2 3 4 5 6 7 8 9 10 11 12 13 func BenchmarkHiParallel (b *testing.B) "GET /hi HTTP/1.0\r\n\r\n" )))if err != nil {func (p *testing.PB) for p.Next() {
执行该基准测试,并对阻塞时间类型数据(block.prof)进行采样与剖析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 ~/Sites/go/src/pprof/sample ❯ go test -bench=Parallel$ -benchtime=2s -blockprofile=block.profsample sample 3.516ssample ❯ go tool pprof sample .test block.profFile : sample .test Type : delaytype "help" for commands, "o" for options)for 5.27s, 100% of 5.27s total out of 15sum % cum cum%sample .BenchmarkHiParallelRun run list handleHiTotal : 5.27ssample .handleHi in /Users/ezreal/Sites/go/src/pprof/sample /main.goTotal return bytes.NewBuffer(make([]byte, 128))if !rxOptionalID.MatchString(r.FormValue("coloe" )) {Error (w, "Optional color is invalid" , http.StatusBadRequest)return Get ().(*bytes.Buffer)"<h1 style='color: " )"color" ))"'>Welcome!</h1>You are visitor number " )append (b, '!')log .Printf("Starting on port 8080" )"/hi" , handleHi)log .Fatal(http.ListenAndServe("127.0.0.1:8080" , nil))
handleHi并未出现在top10排名中。进一步展开handleHi代码后,我们发现整个函数并没有阻塞goroutine过长时间的环节,因此无须对handleHi进行任何这方面的优化。当然这也源于Go标准库对regexp包的Regexp.MatchString方法做过针对并发的优化(也是采用sync.Pool)。
总结 通过性能基准测试判定程序是否存在性能瓶颈,如存在,可通过Go工具链中的pprof对程序性能进行剖析;
性能剖析分为两个阶段——数据采集和数据剖析;go tool pprof工具支持多种数据采集方式,如通过性能基准测试输出采样结果和独立程序的性能数据采集;go tool pprof工具支持多种性能数据采样类型,如CPU类型(-cpuprofile)、堆内存分配类型(-memprofile)、锁竞争类型(-mutexprofile)、阻塞时间数据类型(-block-profile)等;
go tool pprof支持两种主要的性能数据剖析方式,即命令行交互式和Web图形化方式;
在不明确瓶颈原因的情况下,应优先对CPU类型和堆内存分配类型性能采样数据进行剖析。