MySQL 主从延迟怎么解决
主从延迟真的可以解决吗
大家都知道,主-从也是一种分布式系统,分布式系统有个著名的理论:CAP。
CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
一般来说,P是必要的,A和C二选一。也就是需要在一致性和可用性两者之间做出抉择。
关系型数据Mysql是我们常用的数据库,如果要保持主节点与从节点的强一致性,而放弃了Mysql的可用性,试想一下,客户端在主从同步保持一致性期间无法写数据或者读数据,造成mysql不可用,比如长事务导致从库同步延迟。不知道你是否会选择这样的数据库!
因此,主从延迟无法做到强一致性,只能最终一致。
MySQL 主从同步原理
MySQL 主从同步是指数据可以从一个MySQL数据库服务器主节点复制到一个或多个从节点。
MySQL 默认采用异步复制方式,这样从节点不用一直访问主服务器来更新自己的数据,数据的更新可以在远程连接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
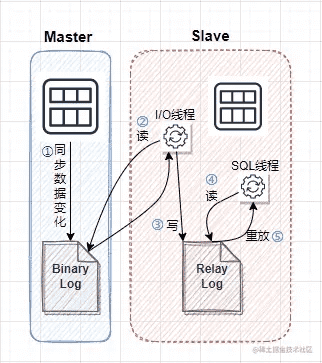
- Master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,则将其改变写入二进制日志中;
- Slave服务器会在一定时间间隔内对Master二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O线程请求Master二进制事件.
- 同时主节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至Slave节点本地的ReplayLog中,Slave节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,使得其数据和Master节点的保持一致,最后I/O线程和SQL线程将进入睡眠状态,等待下一次被唤醒。
主从同步延迟较大的原因
表缺乏主键或者索引
当binlog的存储格式为row的情况下,如果表缺乏主键或索引,在执行UPDATE、DELETE的时候可能会造成从库延迟骤增。
比如,订单order表有1000万的数据,根据order_num更新status时,如果没有order_num的单索引或者联合索引,主库更新会全表扫描,因此执行时间较长,比如30s。
1 | |
虽然I/O线程能够迅速从主库中读取到update操作,但是Slave节点的SQL线程从ReplayLog中读取到update语句,并进行重播,由于全表扫描,因此,同样延迟30s执行,主库和从库就产生了较长时间的延迟。
显而易见,解决办法就是:创建主键或者索引,避免全表扫描。
bin log 格式为 row
此外,还有一个更特殊而普遍的情况: 主库产生的日志记在binlog里是row格式的,不是一条sql,而是这条sql所影响的具体值的修改。主库执行一条sql修改了2万行,只需要全表扫描一次,但是,备库就要执行2万条sql语句,全表扫描2万次。
解决思路:这种方式的话就需要修改为mixed格式
主库 DML 请求频繁
主库写请求较多,有大量insert、delete、update并发操作,短时间产生了大量的binlog。主库并发写入数据,而从库SQL Thread为单线程回放日志,很容易造成relaylog堆积,产生延迟。如下图:
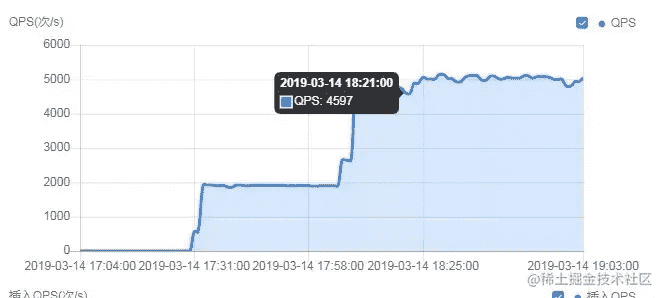
可以看出,在17:58分左右QPS突增,查看控制台上的写相关QPS,也有相应提升。而QPS突增的时间,对应的延时也在逐步上升,如下图所示。
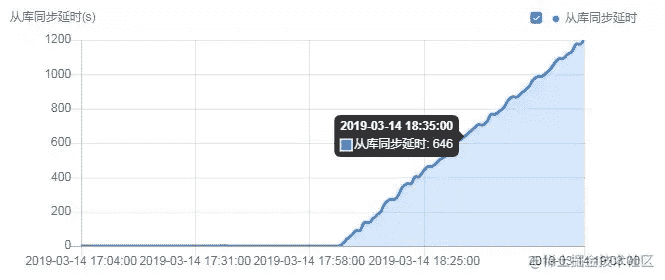
解决思路:如果是MySQL 5.7以下的版本,可以做分片(sharding),通过水平扩展(scale out)的方法打散写请求,提升写请求写入binlog的并行度。
如果是MySQL 5.7以上的版本,在MySQL 5.7,使用了基于逻辑时钟(Group Commit)的并行复制。而在MySQL 8.0,使用了基于Write Set的并行复制。这两种方案都能够提升回放binlog的性能,减少延时。
主库写 binlog 不及时
参数sync_binlog控制binlog从内存写入磁盘的控制开关,5.6默认为0,从5.7开始默认为1。
sync_binlog=1:每次事务提交都立即刷新binlog到磁盘(双一标准中的其一)。
sync_binlog=0:每次事务提交不立即写入磁盘,靠操作系统判断什么时候写入。
磁盘IO不行,binlog写入比较慢。建议binlog使用ssd。
binlog 刷盘时机参数 sync_binlog
- sync_binlog = 0的时候,表示每次提交事务都只write,不fsync,后续交由操作系统决定何时将数据持久化到磁盘;
- sync_binlog = 1的时候,表示每次提交事务都会write,然后马上执行 fsync。
- sync_binlog = N(N>1)的时候,表示每次事务都会write,但是累计到N个事务才会fsync。
主库执行大事务
大事务指一个事务的执行,耗时非常长。常见产生大事务的语句有: 使用了大量速度很慢的导入数据语句,比如:INSERT INTO 、tb、LOAD DATA INFILE等; 使用了UPDATE、DELETE语句,对于一个很大的表进行全表的UPDATE和DELETE等。 当这个事务在从库执行回放执行操作时,就有可能会产生主从复制延时。
解决办法:拆分大事务语句到若干小事务中,这样能够进行及时提交,减小主从复制延时。
主库对大表执行DDL语句
DDL全称为 Data Definition Language ,指一些对表结构进行修改操作的语句,比如,对表加一个字段或者加一个索引等等。当DDL对主库大表执行DDL语句的情况下,可能会产生主从复制延时。DDL导致的主从复制延时的原因和大事务类似,也是因为从库执行DDL的binlog较慢而产生了主从复制延时。
遇到这种情况,我们主要通过SHOW PROCESSLIST或对information_schema.innodb_trx做查询,来找到阻塞DDL语句,并KILL掉相关查询,让DDL正常在从库执行。
主库与从库配置不一致
如果主库和从库使用了不同的计算资源和存储资源,或者使用了不同的内核调教参数,可能会造成主从不一致。
各种硬件或者资源的配置差异都有可能导致主从的性能差异,从而导致主从复制延时发生:
硬件上:比如,主库实例服务器使用SSD磁盘,而从库实例服务器使用普通SAS盘,那么主库产生的写入操作在从库上不能马上消化掉,就产生了主从复制延时;
配置上:比如,RAID卡写策略不一致、OS内核参数设置不一致、MySQL落盘策略不一致等,都是可能的原因。
解决思路:考虑尽量统一DB机器的配置(包括硬件及选项参数)。甚至对于某些OLAP业务,从库实例硬件配置需要略高于主库。
从库自身压力过大
从库执行大量select请求,或业务大部分select请求被路由到从库实例上,甚至大量OLAP业务,或者从库正在备份等。 此时可能造成cpu负载过高,io利用率过高等,导致SQL Thread应用过慢。
解决思路:可以增加从服务器的个数,尽量的分散从服务器的压力。
总结
客户端
- 表缺乏索引或者主键,建议新增主键或者索引。
- 大事务,建议将大事务拆分为小事务。
服务端
- bin log 格式导致,建议将bin log 格式修改为 mixed。
- 主库写 bin log 不及时,建议修改 binlog 刷盘时机。
- 主库从库服务器配置差异,建议提高从服务器的配置。
- 从库自身压力过大,建议增加从服务器的个数。
- 主库对大表执行DDL语句,查出对应的DDL语句处理掉。
- 主库DML请求过于频繁,建议做分片。