Victoriametrics 简介
简介
VictoriaMetrics集群方案,除了有单节点方案的优点以外,还可以做到水平扩容,当有大量数据存储时,VictoriaMetrics集群方案是个不错的选择。
一般建议是100w/s以下的数据点抓取,使用单节点版,单节点版可以省更多的CPU、内存、磁盘资源。
但是,当遇到如下问题可以考虑集群方案:
- 抓取数据点过高:大于100w/s数据点抓取(如果lable内容过多,会低于这个值)
- 海量数据存储:单机磁盘容量已经满足不了,更长时间的存储、海量数据存储需求
- 要更高性能:要求更高的写入和查询性能
- 原生高可用:VictoriaMetrics集群方案,原生支持高可用
- 多租户:想要数据多租户管理
架构
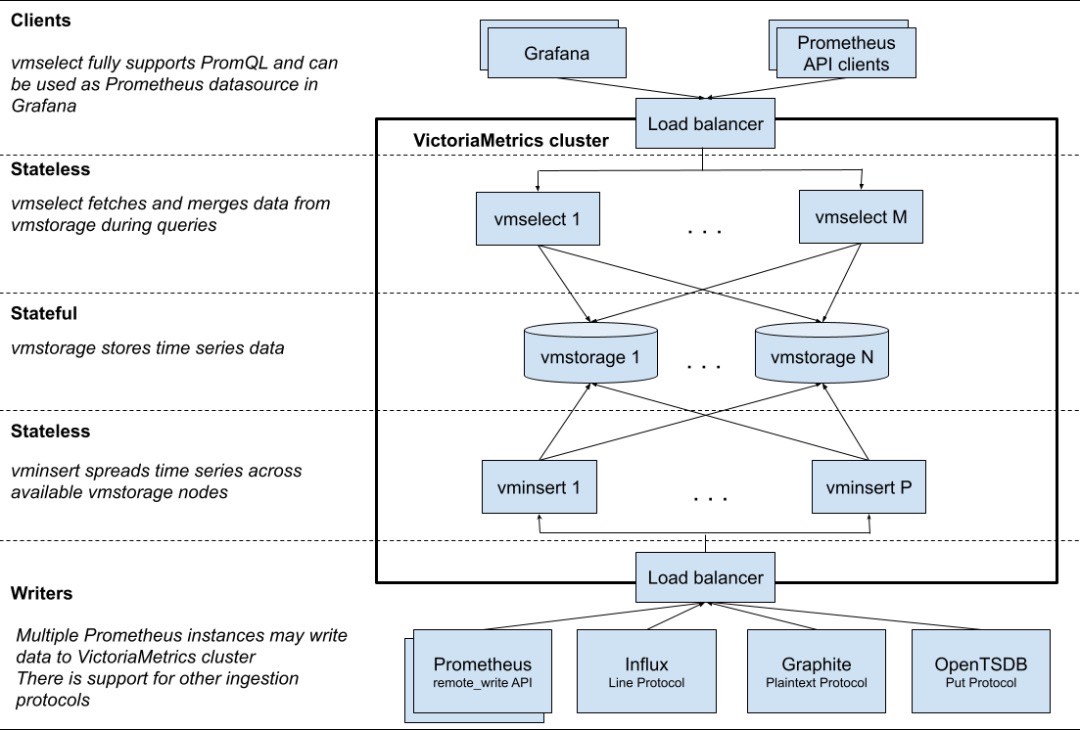
Victoriametrics架构
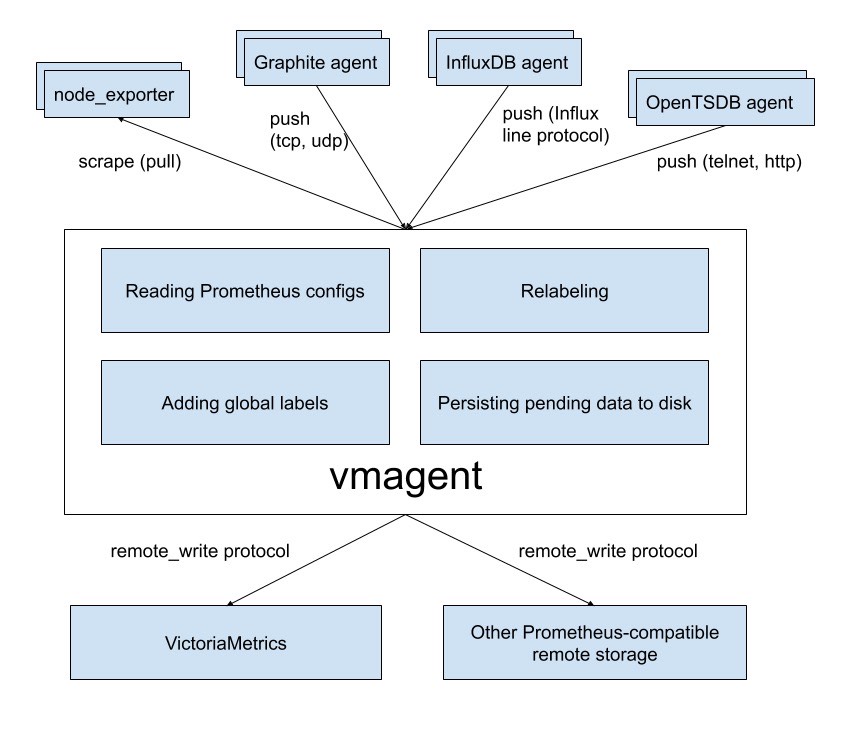
Vmagent 架构 简介
组件服务和作用
| 组件 | 作用 | 端口 | 其他 |
|---|---|---|---|
| vmstorage | 数据存储,以及查询结果返回 | 8482 | |
| vminsert | 数据录入,可实现类似分片、副本功能 | 8480 | |
| vmselect | 数据查询,汇总和排重数据 | 8481 | |
| vmagent | 数据指标抓取,并支持多种后端存储 | 8429 | 会占用本地磁盘缓存 |
| vmalert | 告警规则相关 | 8880 | 如不需要告警功能可不使用此组件服务 |
| vmauth | 账号认证相关 | 8427 | 不建议用,而且用户名是路由 |
副本、分片及HA
VM集群版,可以实现副本和分片功能,来保证数据的冗余和水平扩容。主要是VM集群版的几个组件服务配合实现。
vmagent
target均摊和自身冗余抓取功能
- promscrape.cluster.membersCount,指定target被vmagent分成多少抓取组
- promscrape.cluster.memberNum,指定当前vmagent,抓取指定target分组
- promscrape.cluster.replicationFactor,单target被多少个vmagent抓取,这里会产生冗余数据,此参数主要是为了保证vmagent的高可用
vminsert
按算法为固定时间序列选择后端存储(分片) 和 控制副本数量(副本)
- replicationFactor,开启副本,并控制副本数量,既 要往多少个vmstorage插入同一份样本数据
vmstorage
数据存储,vmstorage节点间不进行任何交互,都是独立的个体,只靠上层的vminsert,产生副本和分片
- dedup.minScrapeInterval,vmagent会产生replicationFactor份冗余数据,需要此参数,来去除重复数据
vmselect
数据汇总以及返回,当vminsert开启副本后,vmselect必须设置dedup.minScrapeInterval
- dedup.minScrapeInterval,去除指定时间的重复数据
- replicationFactor,当replicationFactor=N,在出现最多N-1个vmstorage不可用或者响应慢时,vmselect查询直接忽略,提升了查询效率
注意
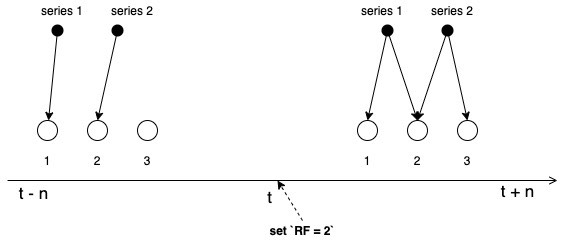
开启副本或修改副本个数(replicationFactor简称RF)后,可能造成数据部分丢失。
下面展示没开副本之前已在收集数据,开了副本之后(RF=2),并且vmselect指定replicationFactor参数,vmselect会当成所有数据都是有副本的,但是 RF=2 之前有一段时间是未开副本收集数据的。
当查 t之前 的series1数据时,1节点 突然故障或者响应慢了,vmselect会认为 2节点有副本数据,其实 t之前 是没有开副本的,所以会导致 series1 丢失 1节点 的数据。如下图:
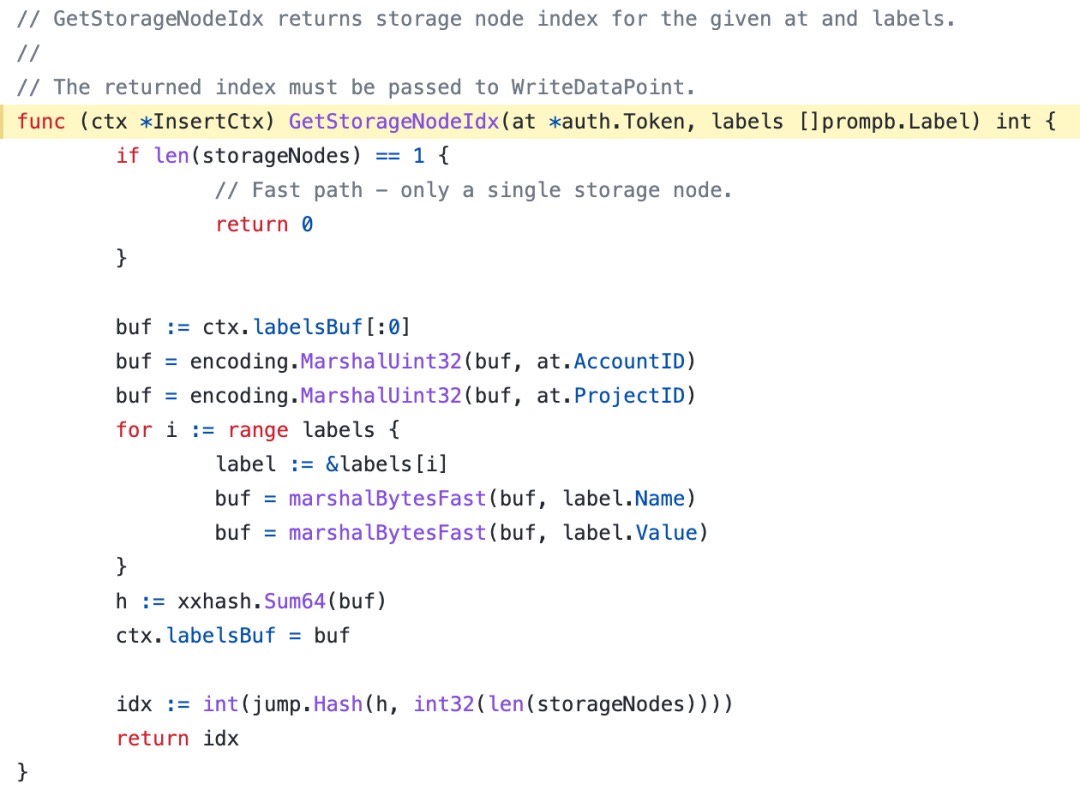
分片原理
如果vminsert后面存在多个vmstorage,vminsert就会对数据进行分片(或者说打散),vminsert主要通过一致性哈希选择vmstorage节点,具体实现如下代码:
分组原理
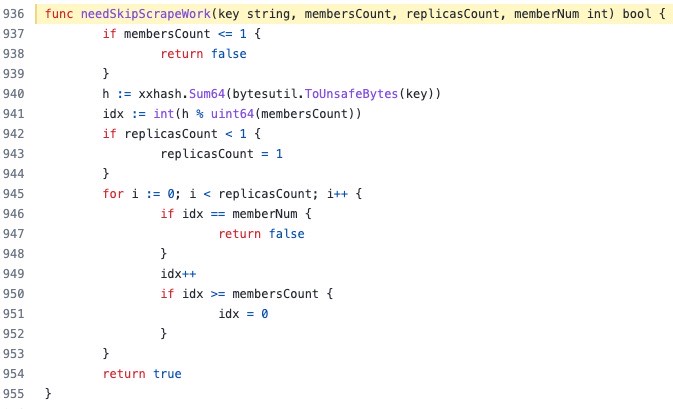
vmagent分组方式,通过vmagent传入的4个参数标识集、组成员总数、当前成员编号、副本数 ,进行判断,是否为当前vmagent要抓取的target,具体实现方式如下代码:
多租户
VM集群版支持多租户概念,可以把不类型的数据,分别放到不同的租户(命名空间)里,每个租户通过 accountID 或 accountID:projectID,在请求的url里做区分。其中:
- accountID和projectID:是[0 .. 2^32)的任意整数,projectID可不写,默认0
- 创建时间:在首次对某个租户录入数据时,自动创建
- 性能:租户的数量不影响性能,主要取决于所有租户的活跃总时间序列,每个租户的数据都均匀分布在后端vmstorage存储
- 隔离:不能跨租户查询
API 示例
API使用方法基本和VM单节点版差不多,主要多了 租户 和 组件服务名 ,
VM集群版querying API 格式:
http://<vmselect>:8481/select/<accountID>/prometheus/<suffix>
下面以查询主机负载为例,对比区别:
1 | |
如上,和Prometheus的API请求区别,主要多了 “/select/6666/prometheus” ,其它API请求类似。
安全认证
目前只有vmagent有自带了httpAuth.username、httpAuth.password的基础认证方式,但最需要有认证功能的vmselect、vminsert、vmstorage却没有,尤其是存在vmui的vmselect。
官方给出的解释是,vmselect、vminsert、vmstorage,一般是在上层就把权限认证解决了,而且因为多租户,每个租户都应该有自己的账号密码,所以没有做全局的基础账号认证,而且也不打算开发。
官方有个vmauth,认证模式比较简单,而且还需要用账号名称做路由标识,没法用同一个账号访问多个组件服务,目前还是建议用nginx做基础账号认证。
容量规划
| 组件 | vCPUs | RAM |
|---|---|---|
| vminsert | ingestion_rate/150K | (active time series / 100w) *1G (less than 1KB per active time series) |
| vmstorage | ingestion_rate/150K | (active time series / 100w) *1G (less than 1KB per active time series) |
| vmselect | 根据读取量评估 | 根据读取量评估 |
故障处理
| 故障组件 | 处理方式 |
|---|---|
| vmselect故障 | 此为无态服务,所有节点配置信息一样,故障后直接扩容即可 |
| vmagent故障 | 开启replicationFactor=N(N>1)后,单个target都会被N节vmagent点抓取数据,所以故障 “小于等于N-1”个节点,都不会影响数据抓取 |
| vminsert故障 | vminsert所有节点,配置信息都一样。而且vmagent开启replicationFactor,所以每个target样本数据都会被写入到多个vminsert,单个vminsert故障不会丢失数据,新部署一个即可 |
| vmstorage故障 | 因为vminsert开启replicationFactor副本,所有target的样本数据都会存在多个vmstorage上,所以故障单个节点,不会丢失数据,只需要等待恢复,或者重新部署单个vmstorage节点 |
容灾处理
victoriametrics提供了一些数据备份的方法vmbackup&&vmrestore 都是一些工具
- 备份方法
1 | |
- 数据恢复
1 | |
扩容方案
当VM集群遇到瓶颈,无非就如下几种场景,可根据情况进行扩容:
- 查询速度过慢
vmselect为无态服务,配置信息都一样,直接扩容,即可解决此问题。 - 数据录入慢
vminsert和vmselect一样,直接扩容即可。 - 容量不足
vmstorage水平扩容来解决此问题,因为vmstorage是有态服务,扩容要配合上游组件服务一起。vmstorage各节点配置一样,直接扩容即可。同时需要把上游的vmselect和vminsert的存储列表(-storageNode)进行更新,然后全部重启。 - 抓取样本量过大
扩容vmagent即可,但需要重新分配所有vmagent对target的分组参数,-promscrape.cluster.membersCount=N 增加总分组数,-promscrape.cluster.memberNum=(0~N-1) 当前vmagent节点所在分组号,修改完后重启所有vmagent。
VM集群版的好处就是灵活,哪里性能不行扩哪里,那种类型组件服务运行在哪类主机上,充分利用系统资源。
简单搭建
具体搭建还需要看自己。
1 | |