Victoriametrics压测
压测目标
victoriametrics 集群版远程存储性能压测。(单机版远程存储官方介绍是 1000k sample/sec无压力)
压测环境
- victoriametrics机器:48c64g 系统盘ssd 890G (主要作为远程存储服务器),ip为192.168.202.83。
- victoriametrics版本: v1.77.2 amd64
- vmstorage实例数:3个,端口分别是8482、18482、28482,主要为vminset和vmselect提供写和读能力。
- vminsert实例数:3个,端口分别是8400、18400、28400,主要对外提供写能力。
- vmselect实例数:3个,端口分别是8481、18481、28481,主要对外提供读能力。
- vmagent实例数:1个,端口8428,主要采集vmstroage、vminsert、vmselect的相关性能指标并在grafana中展示。
其中,vminsert和vmselect使用nginx 反向代理统一对外暴露,vminsert暴露端口7400,vmselect暴露端口7481。
压测步骤
使用prometheus-benchmark进行压测。其流程图如下:
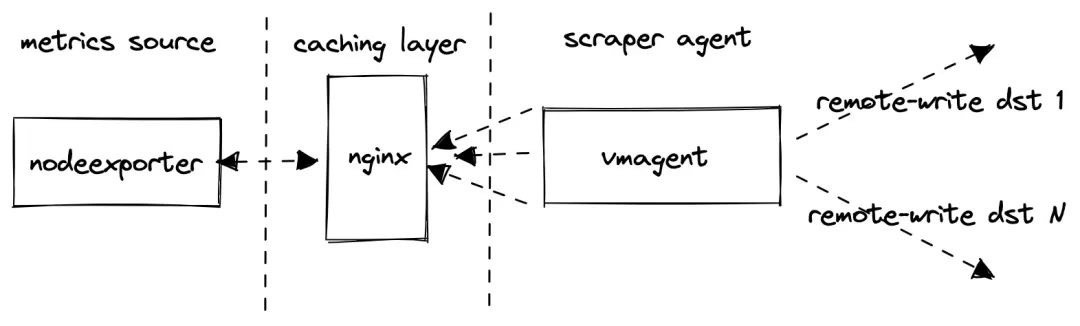
实现原理:
- 使用 node_exporter 用作类似生产环境指标的来源
- 在 node_exporter 前面挂了一个 nginx 用作缓存代理,当抓取太多的指标时,这可以减少 node_exporter 的负载
- 使用 vmagent来抓取 node_exporter指标并通过Prometheus remote_write 协议将它们转发到配置的目标。如果设置了多个目标,则多个 vmagent实例独立地将抓取的数据推送到这些目标去。
- 监控远程存储系统victorametrics的相关指标和性能。
该压测的核心实现就是根据传入的一系列参数不断去更新抓取指标的配置文件,然后 vmagent根据暴露的接口获取其配置 -promscrape.config去抓取指标。
关键压测参数含义解释
targetsCount
targetsCount定义有多少 node_exporter抓取目标被添加到 vmagent的抓取配置中,每个都包含一个唯一的 instance标签,该参数会影响抓取指标的数量和基数。通常,一个 node_exporter会产生大约 815 个唯一指标,因此当 targetsCount设置为1000时,测试会生成大815*100=815K的活跃时间序列。
但是在实际压测中,发现产生的指标大概是1500个。此处细节不太清楚。
scrapeInterval
scrapeInterval定义了抓取每个目标的频率,此参数会影响数据摄取率,间隔越小,数据摄取率越高。
远程存储
remoteStorages包含一个测试的系统列表,将抓取的指标推送过去,如果设置了多个目标,则多个 vmagent实例会分别将相同的数据推送到多个目标。
Churn rate
scrapeConfigUpdatePercent和 scrapeConfigUpdateInterval可用于生成非零的时间序列流失率,这在 Kubernetes 监控中是非常典型的场景。
queryInterval
查询周期,从远程存储中查询,该值可以模拟查询时间,评估远程读性能。
准备工作
在k8s集群中安装prometheus-bench;
下载prometheus-benchmark1
2$ git clone https://github.com/VictoriaMetrics/prometheus-benchmark
$ cd prometheus-benchmark然后修改配置文件,现在项目代码中默认带一个单节点的 VictoriaMetrics,但是 Charts 模板中没有添加 Service 对象,操作不是很方便,我们添加一个 chart/templates/vmsingle/service.yaml 文件,内容如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16apiVersion: v1
kind: Service
metadata:
name: {{ include "prometheus-benchmark.fullname" . }}-vmsingle
namespace: {{ .Release.Namespace }}
labels:
{{- include "prometheus-benchmark.labels" . | nindent 4 }}
spec:
type: NodePort
selector:
job: vmsingle
{{- include "prometheus-benchmark.selectorLabels" . | nindent 4 }}
ports:
- port: 8428
targetPort: 8428
nodePort: 30136复制chart下面的example-values.yaml文件为values.yaml,修改如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74# vmtag is a docker image tag for VictoriaMetrics components,
# which run inside the prometheus-benchmark - e.g. vmaget, vmalert, vmsingle.
vmtag: "v1.77.1"
# targetsCount defines the number of nodeexporter instances to scrape.
# This option allows to configure the number of active time series to push
# to remoteStorages.
# Every nodeexporter exposes around 815 unique metrics, so when targetsCount
# is set to 1000, then the benchmark generates around 815*100=815K active time series.
targetsCount: 2000
# scrapeInterval defines how frequently to scrape nodeexporter targets.
# This option allows to configure data ingestion rate per every remoteStorages.
# For example, if the benchmark generates 815K active time series and scrapeInterval
# is set to 10s, then the data ingestion rate equals to 815K/10s = 81.5K samples/sec.
scrapeInterval: 10s
# queryInterval is how often to send queries from files/alerts.yaml to remoteStorages.readURL
# This option can be used for tuning read load at remoteStorages.
# It is a good rule of thumb to keep it in sync with scrapeInterval.
queryInterval: 10s
# scrapeConfigUpdatePercent is the percent of nodeexporter targets
# which are updated with unique label on every scrape config update
# (see scrapeConfigUpdateInterval).
# This option allows tuning time series churn rate.
# For example, if scrapeConfigUpdatePercent is set to 1 for targetsCount=1000,
# then around 10 targets gets updated labels on every scrape config update.
# This generates around 815*10=8150 new time series every scrapeConfigUpdateInterval.
scrapeConfigUpdatePercent: 1
# scrapeConfigUpdateInterval specifies how frequently to update labels
# across scrapeConfigUpdatePercent nodeexporter targets.
# This option allows tuning time series churn rate.
# For example, if scrapeConfigUpdateInterval is set to 10m for targetsCount=1000
# and scrapeConfigUpdatePercent=1, then around 10 targets gets updated labels every 10 minutes.
# This generates around 815*10=8150 new time series every 10 minutes.
scrapeConfigUpdateInterval: 10m
# writeConcurrenty is the number of concurrent tcp connections to use
# for sending the data to the tested remoteStorages.
# Increase this value if there is a high network latency between prometheus-benchmark
# components and the tested remoteStorages.
writeConcurrency: 16
# remoteStorages contains a named list of Prometheus-compatible systems to test.
# These systems must support data ingestion via Prometheus remote_write protocol.
# These systems must also support Prometheus querying API if query performance
# needs to be measured additionally to data ingestion performance.
remoteStorages:
# the name of the remote storage to test.
# The name is added to remote_storage_name label at collected metrics
vm-0:
# writeURL should contain the url, which accepts Prometheus remote_write
# protocol at the tested remote storage.
# For example, the following urls may be used for testing VictoriaMetrics:
# - http://<victoriametrics-addr>:8428/api/v1/write for single-node VictoriaMetrics
# - http://<vminsert-addr>:8480/insert/0/prometheus/api/v1/write for cluster VictoriaMetrics
writeURL: "http://192.168.202.83:7480/insert/0/prometheus/api/v1/write"
# readURL is an optional url when query performance needs to be tested.
# The query performance is tested by sending alerting queries from files/alerts.yaml
# to readURL.
# For example, the following urls may be used for testing query performance:
# - http://<victoriametrics-addr>:8428/ for single-node VictoriaMetrics
# - http://<vmselect-addr>:8481/select/0/prometheus/ for cluster VictoriaMetrics
readURL: "http://192.168.202.83:7481/select/0/prometheus/"
# writeBearerToken is an optional bearer token to use when writing data to writeURL.
writeBearerToken: ""
# readBearerToken is an optional bearer token to use when querying data from readURL.
readBearerToken: ""
# vm-1:
# writeURL: "http://victoria-metrics-victoria-metrics-cluster-vminsert.default.svc.cluster.local:8480/insert/1/prometheus/api/v1/write"
# readURL: "http://victoria-metrics-victoria-metrics-cluster-vmselect.default.svc.cluster.local:8481/select/1/prometheus/"同时victoriametrics中使用的是pvc,我没使用pvc。直接注释掉了。
启动命令:
1
NAMESPACE=prom-bench make install1
2
3
4
5
6
7
8
9
10
11$ kubectl get pods
NAME READY STATUS RESTARTS AGE
grafana-db468ccf9-mtn87 1/1 Running 0 90m
my-bench-prometheus-benchmark-nodeexporter-76c497cf59-m5k66 2/2 Running 0 49m
my-bench-prometheus-benchmark-vmagent-vm-0-6bcbbb5fd8-8rhcx 2/2 Running 0 49m
my-bench-prometheus-benchmark-vmalert-vm-0-6f6b565ccc-snsk5 2/2 Running 0 49m
my-bench-prometheus-benchmark-vmsingle-585579fbf5-cpzhg 1/1 Running 0 49m
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-bench-prometheus-benchmark-nodeexporter ClusterIP 10.96.156.144 <none> 9102/TCP 50m
my-bench-prometheus-benchmark-vmsingle ClusterIP 10.96.75.242 <none> 8428/TCP 50m该命令会用helm安装。
删除命令:
1
NAMESPACE=prom-bench make delete更多命令查看github的README。
压测过程中,修改values.yaml中的targetsCount增加指标量。然后再启动。
在victoriametrics机器上安装victoriametrics cluster。并对外暴露http://192.168.202.83:7480/insert/0/prometheus/api/v1/write 写接口和 http://192.168.202.83:7481/select/0/prometheus/ 读接口。
在github上下载最新安装包:victoriametrics下载1
2$ mkdir -p /opt/victoria
$ tar -zxvf victoria-metrics-amd64-v1.77.2-cluster.tar.gz -C /opt/victoria/启动服务:
vmstorage_start.sh1
2
3nohup ./vmstorage-prod -loggerTimezone Asia/Shanghai -storageDataPath ./data/vmstorage1-data -httpListenAddr :8482 -vminsertAddr :8400 -vmselectAddr :8401 &> ./log/vmstor1.log &
nohup ./vmstorage-prod -loggerTimezone Asia/Shanghai -storageDataPath ./data/vmstorage2-data -httpListenAddr :18482 -vminsertAddr :18400 -vmselectAddr :18401 &> ./log/vmstor2.log &
nohup ./vmstorage-prod -loggerTimezone Asia/Shanghai -storageDataPath ./data/vmstorage3-data -httpListenAddr :28482 -vminsertAddr :28400 -vmselectAddr :28401 &> ./log/vmstor3.log &vminsert_start.sh
1
2
3nohup ./vminsert-prod -httpListenAddr :8480 -storageNode=127.0.0.1:8400,127.0.0.1:18400,127.0.0.1:28400 &> ./log/vminsert1.log &
nohup ./vminsert-prod -httpListenAddr :18480 -storageNode=127.0.0.1:8400,127.0.0.1:18400,127.0.0.1:28400 &> ./log/vminsert2.log &
nohup ./vminsert-prod -httpListenAddr :28480 -storageNode=127.0.0.1:8400,127.0.0.1:18400,127.0.0.1:28400 &> ./log/vminsert3.log &vmselect_start.sh
1
2
3nohup ./vmselect-prod -httpListenAddr :8481 -storageNode=127.0.0.1:8401,127.0.0.1:18401,127.0.0.1:28401 &> ./log/vmselect1.log &
nohup ./vmselect-prod -httpListenAddr :18481 -storageNode=127.0.0.1:8401,127.0.0.1:18401,127.0.0.1:28401 &> ./log/vmselect2.log &
nohup ./vmselect-prod -httpListenAddr :28481 -storageNode=127.0.0.1:8401,127.0.0.1:18401,127.0.0.1:28401 &> ./log/vmselect.log &启动nginx进行反代:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34upstream vminsert {
server 127.0.0.1:8480 weight=10 max_fails=3 fail_timeout=30s;
server 127.0.0.1:18480 weight=10 max_fails=3 fail_timeout=30s;
server 127.0.0.1:28480 weight=10 max_fails=3 fail_timeout=30s;
}
server {
listen 7480;
server_name localhost;
location / {
proxy_pass http://vminsert;
proxy_connect_timeout 30s;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
upstream vmselect {
server 127.0.0.1:8481 weight=10 max_fails=3 fail_timeout=30s;
server 127.0.0.1:18481 weight=10 max_fails=3 fail_timeout=30s;
server 127.0.0.1:28481 weight=10 max_fails=3 fail_timeout=30s;
}
server {
listen 7481;
server_name localhost;
location / {
proxy_pass http://vmselect;
proxy_connect_timeout 30s;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}各起三个服务,然后用nginx 反代vminsert和vmselect统一对外提供服务。
在victoriametrics机器上安装vmagent,采集vmstorage、vminsert、vmselect相关指标。
下载vmagent,注意下载的包名是vmutils开头的。
解压然后启动vmagent。
vmagent_start.sh1
nohup ./vmagent-prod -promscrape.config=./prometheus.yaml -remoteWrite.url=http://192.168.202.83:7480/insert/0/prometheus/api/v1/write -httpListenAddr=0.0.0.0:8429 > ./vmagent.log 2>&1 &在grafana上添加相关面板。
我添加了两个面板。
第一个是vmagent,设置的grafana源为k8s master node的ip和nodePort端口30136。此处自己根据情况修改。该面板主要展示抓取情况和发送情况。第二个是VictoriaMetrics - cluster,设置的grafana源为http://192.168.202.83:7481/select/0/prometheus/ 该面板主要展示victiorametrics组件的情况。
其中压力位相关的查询都是在grafana中的explore中查询的,数据源是第一个。
压测结果
3k Target
压测样本配置
- targetsCount 设置为3000
- scrapeInterval设置为10s
- remoteStorages writeURL: “http://192.168.202.83:7480/insert/0/prometheus/api/v1/write“
- writeConcurrency设置为16,并发写。
获取的速率大约为 450k样本/秒
1 | |
指标观测
可以看到,抓取3000target没有任何错误。
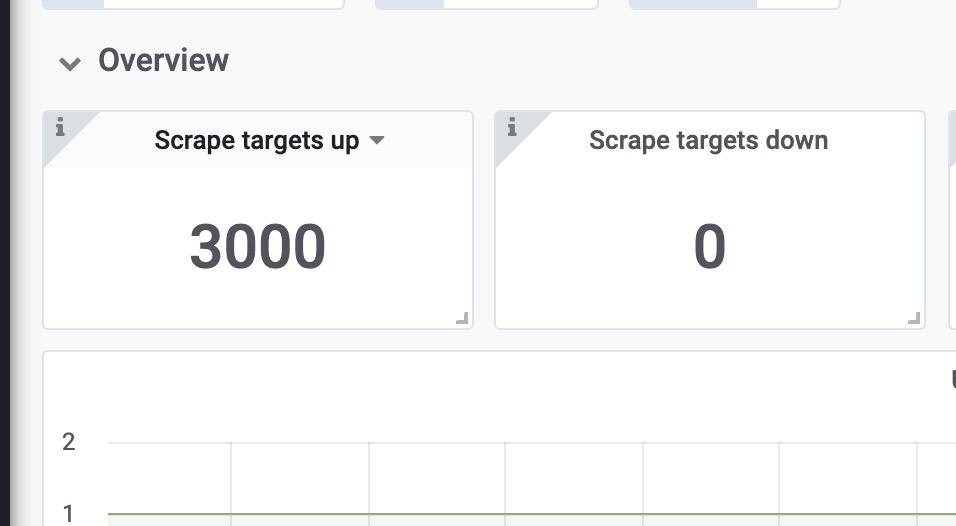
获取样本速率,460k左右,符合预期。
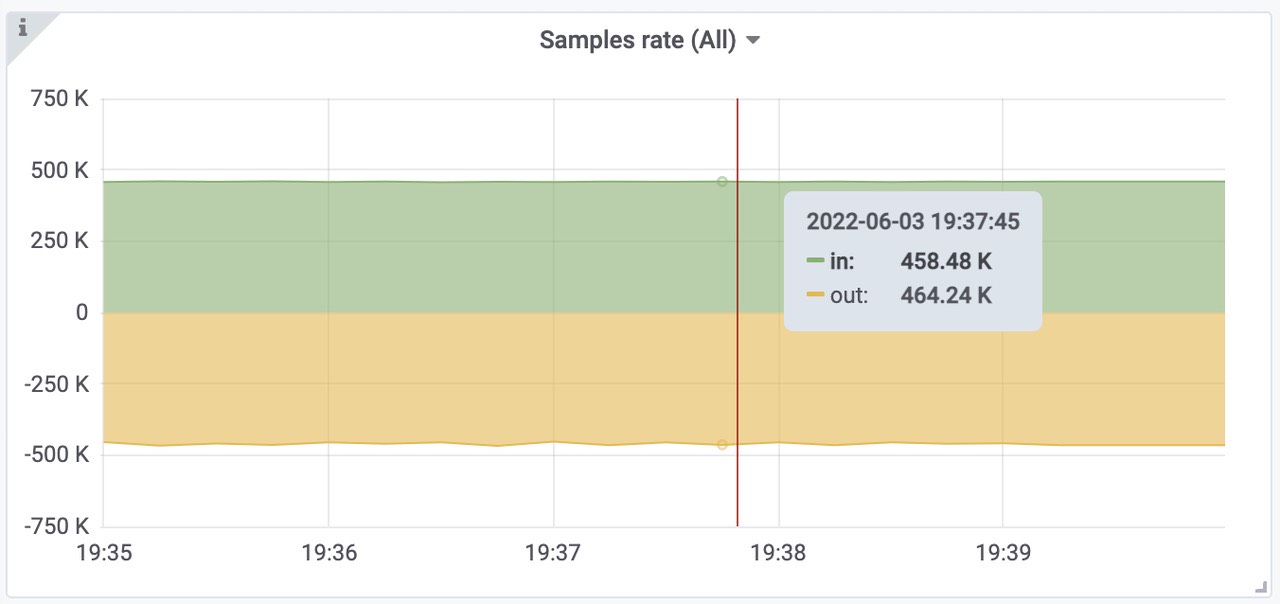
插入到远程存储中的样本数速率为每秒460k。
victoriametrics各组件的日志情况,正常。
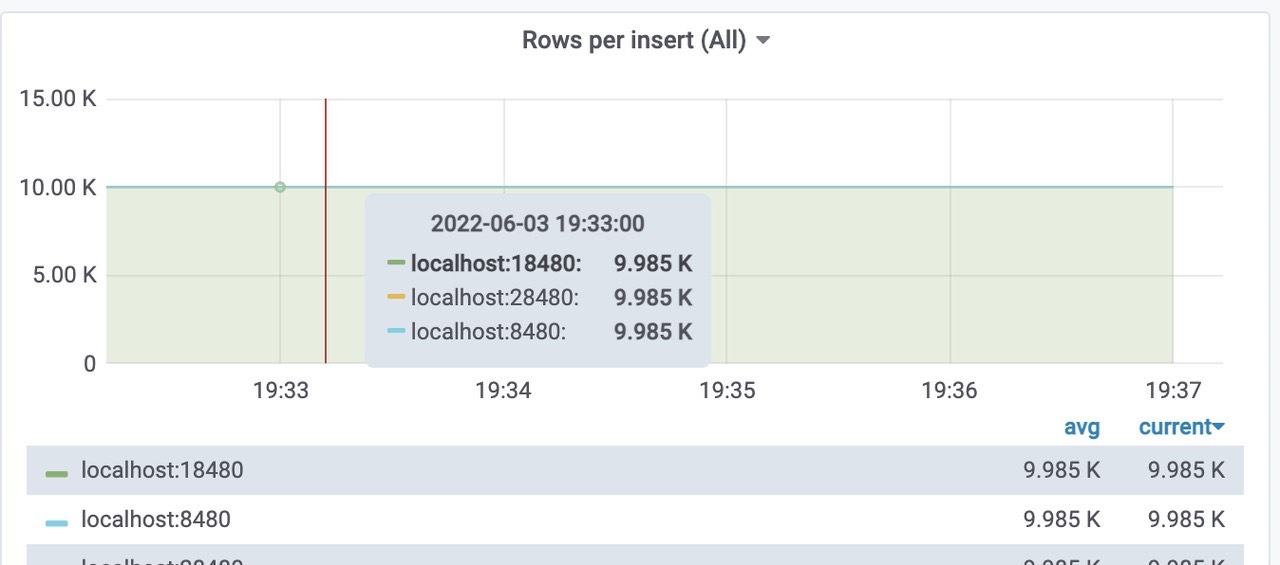
每个远程存储的insert 的 Rows per insert 大概都是10k。
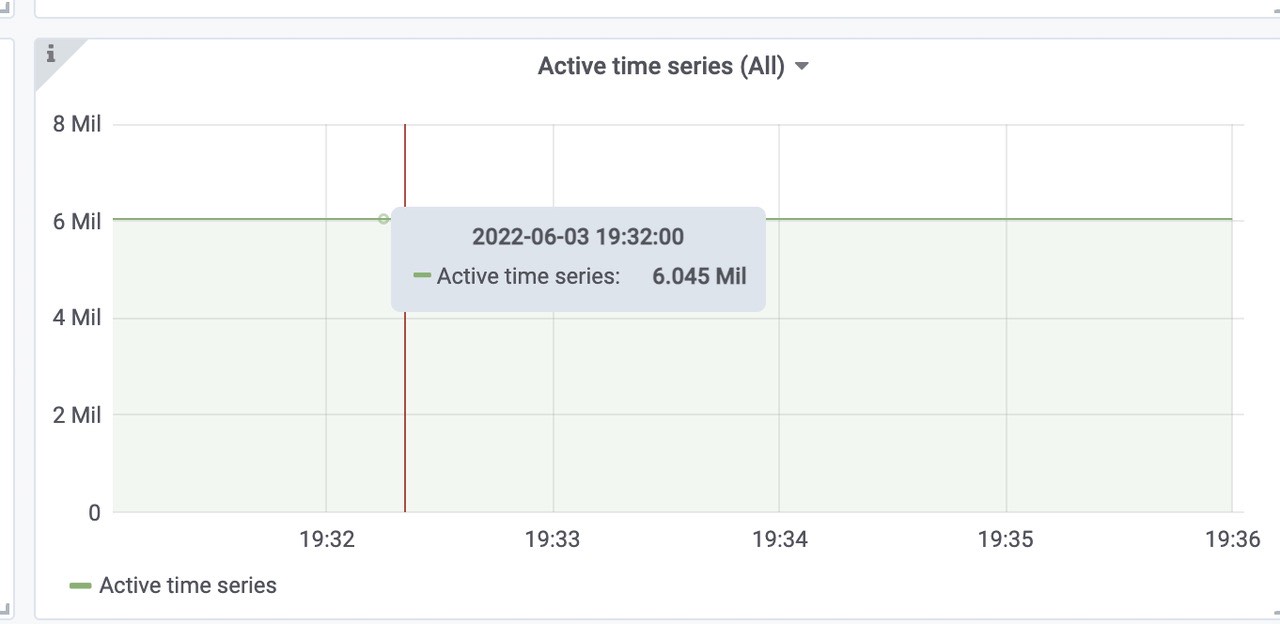
活跃的时间线大概为6Mil左右。
成功插入到vmstorage 中的速率
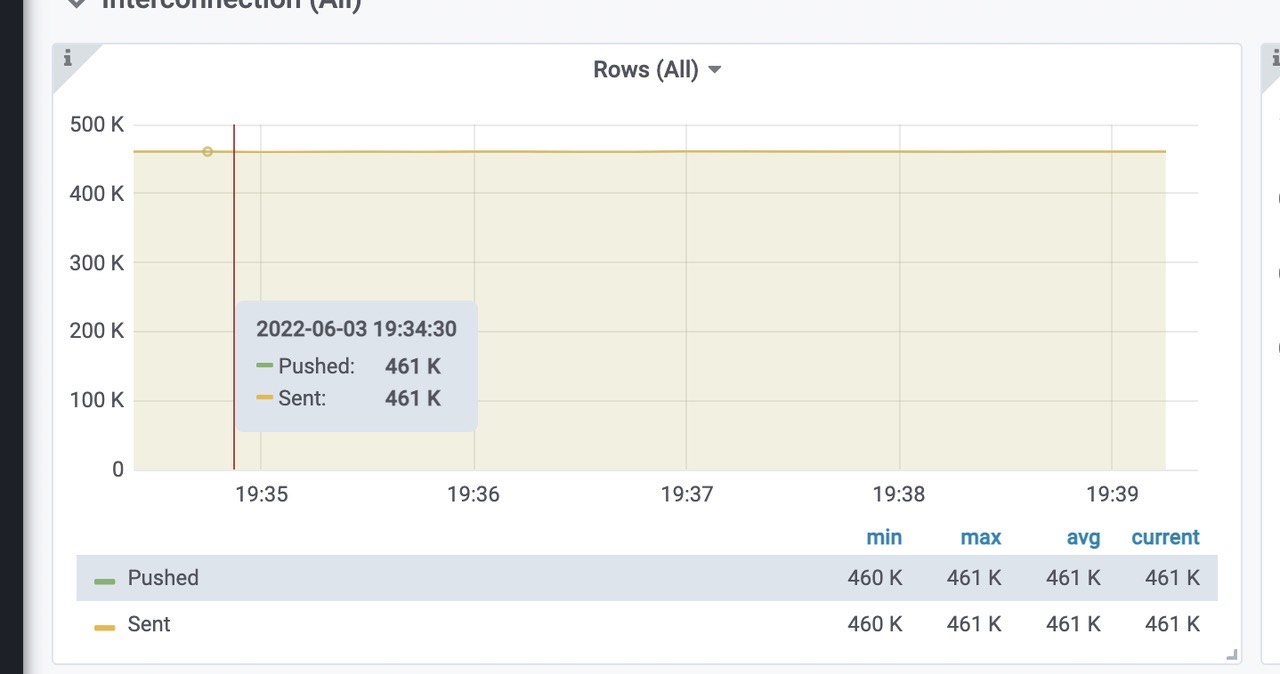
pushed - 在发送之前,将行添加到内部插入器缓冲区中
sent - 成功将行传输到存储节点vmstorage每秒插入的速率,三个storage,平均每个153k
victoriametrics各组件的内存使用情况(vmselect、vminsert、vmstorage)。
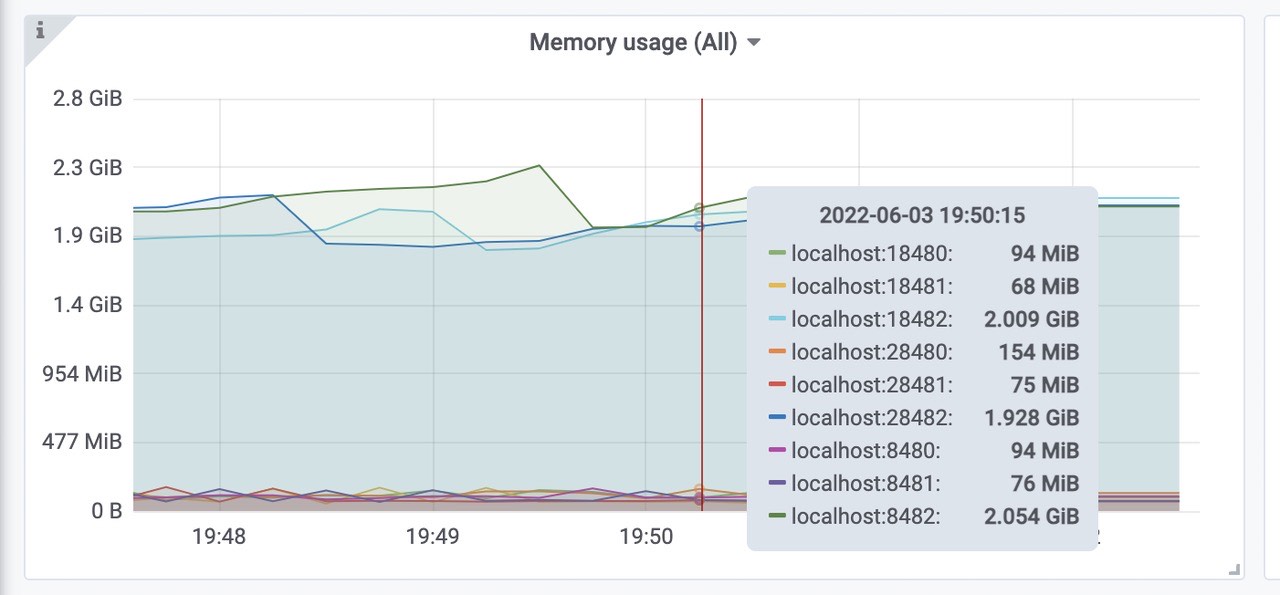
三个vmstorage平均内存使用为2Gib左右,总共使用了6Gib内存左右。
三个vmselect平均使用内存为70Mib左右,总共使用了210Mib内存左右。
三个vminsert平均使用内存为120Mib左右,总共使用了360Mib内存左右。cpu使用
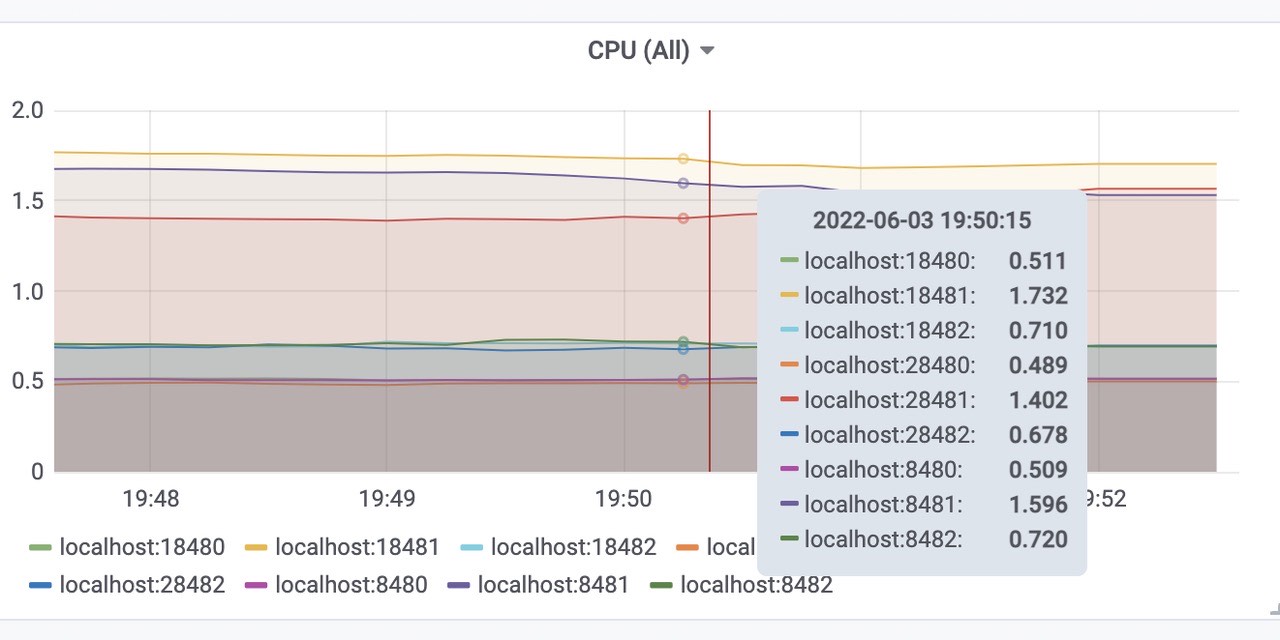
三个vmstorage平均CPU使用为1.6核左右,总共使用了4.8核左右。
三个vmselect平均使用CPU为0.5核左右,总共使用了1.5核左右。
三个vminsert平均使用CPU为0.7核左右,总共使用了2.1核内存左右。Victoriametrics 各组件tcp连接数
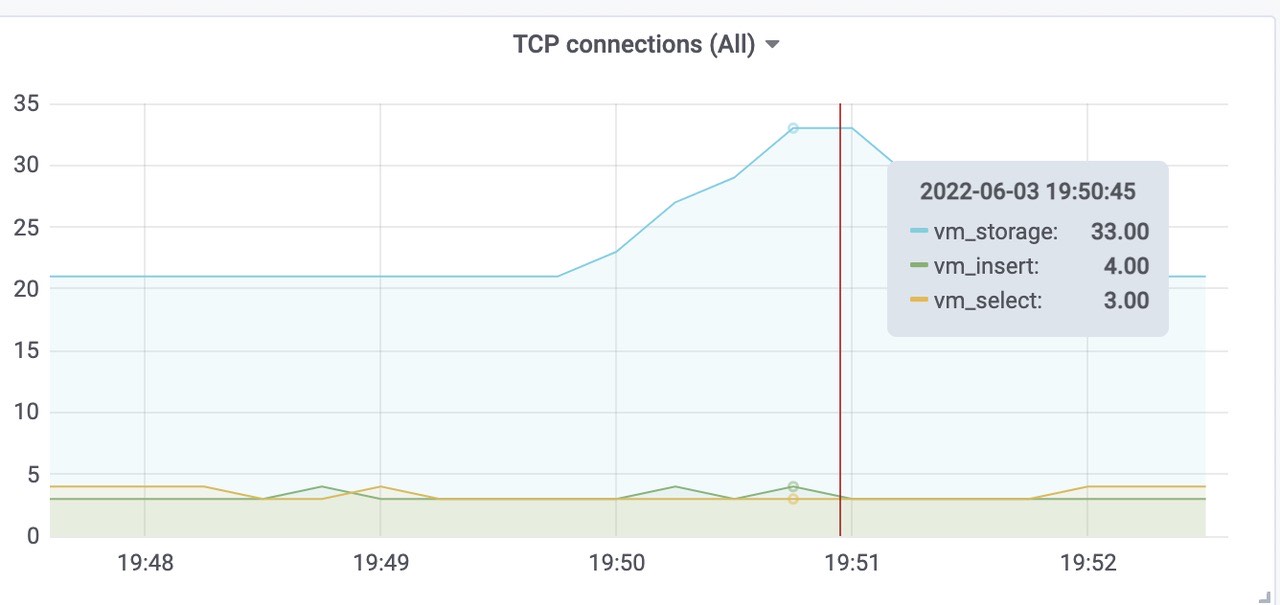
总样本数(包括之前2000 target采集的样本)
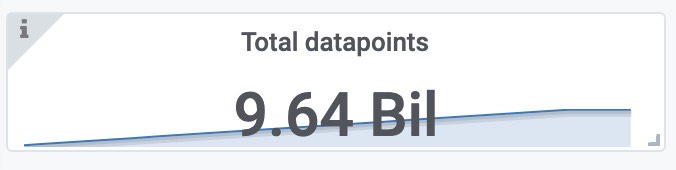
使用磁盘空间(包括之前2000 target采集的样本)
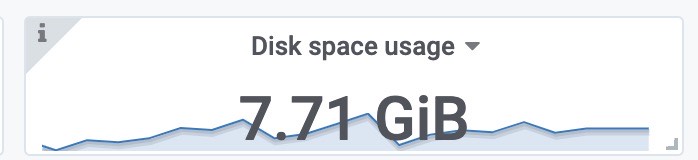
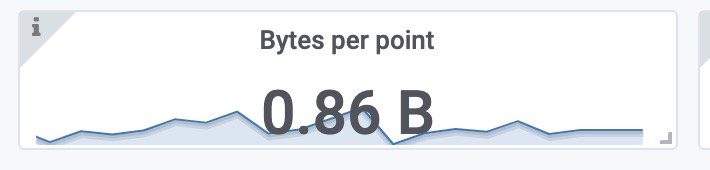
每个样本的大小
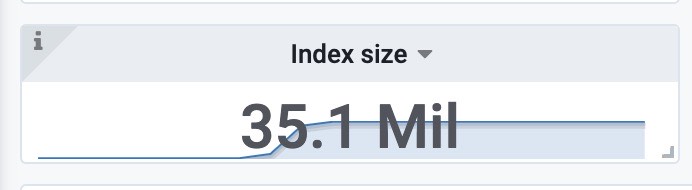
索引文件大小
压力位观测
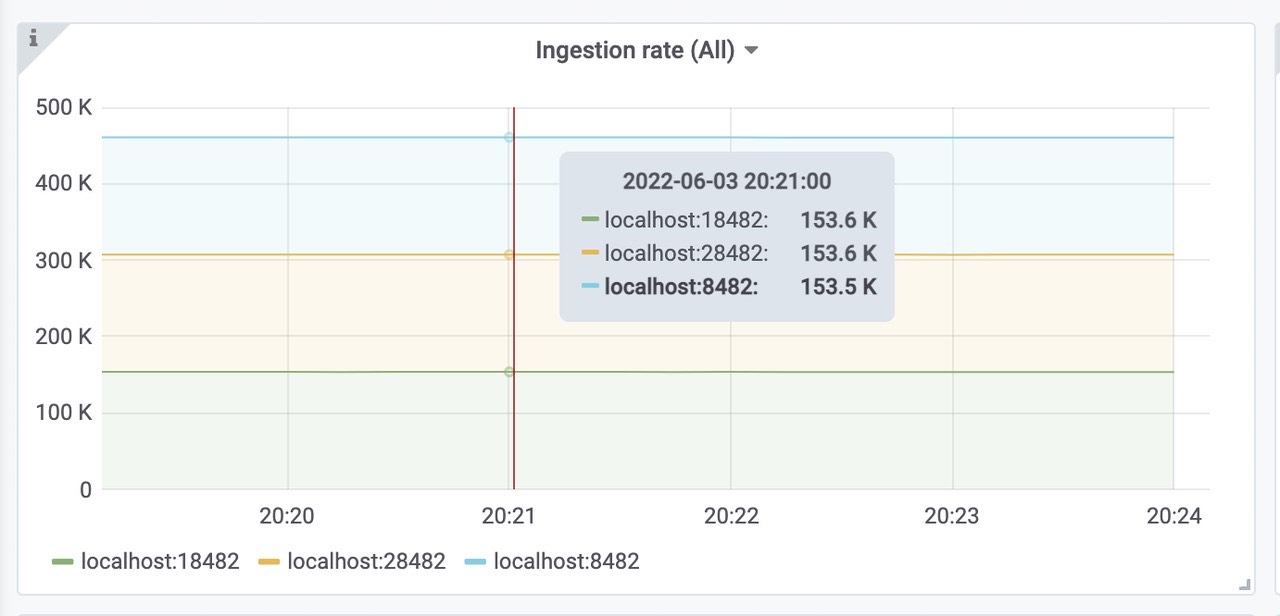
数据摄取率。
1
sum(rate(vm_promscrape_scraped_samples_sum{job="vmagent"})) by (remote_storage_name)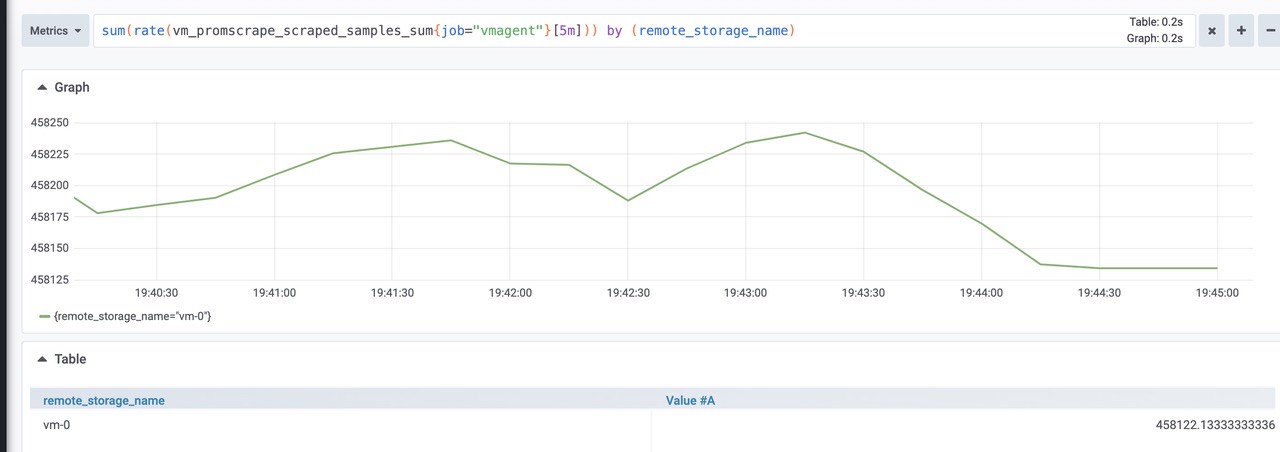
由图可知:大概是460k左右将数据包发送到配置的远程存储时丢弃的数据包数。如果该值大于零,则远程存储拒绝接受传入的数据。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_packets_dropped_total{job="vmagent"})) by (remote_storage_name)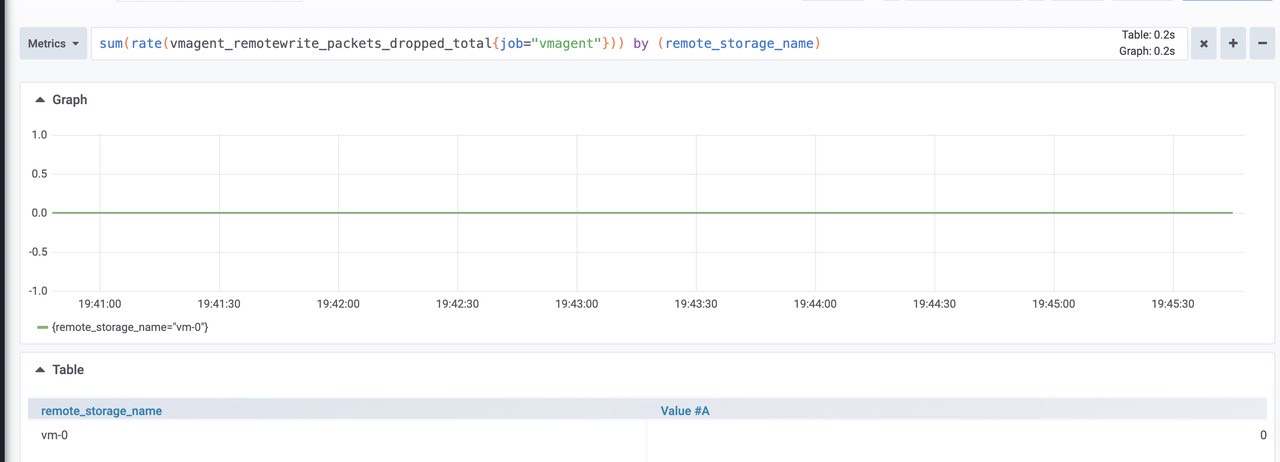
由图可知:丢弃数据包为0,正常。将数据发送到远程存储时的重试次数。如果该值大于零,那么这表明远程存储无法处理工作负载。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_retries_count_total{job="vmagent"})) by (remote_storage_name)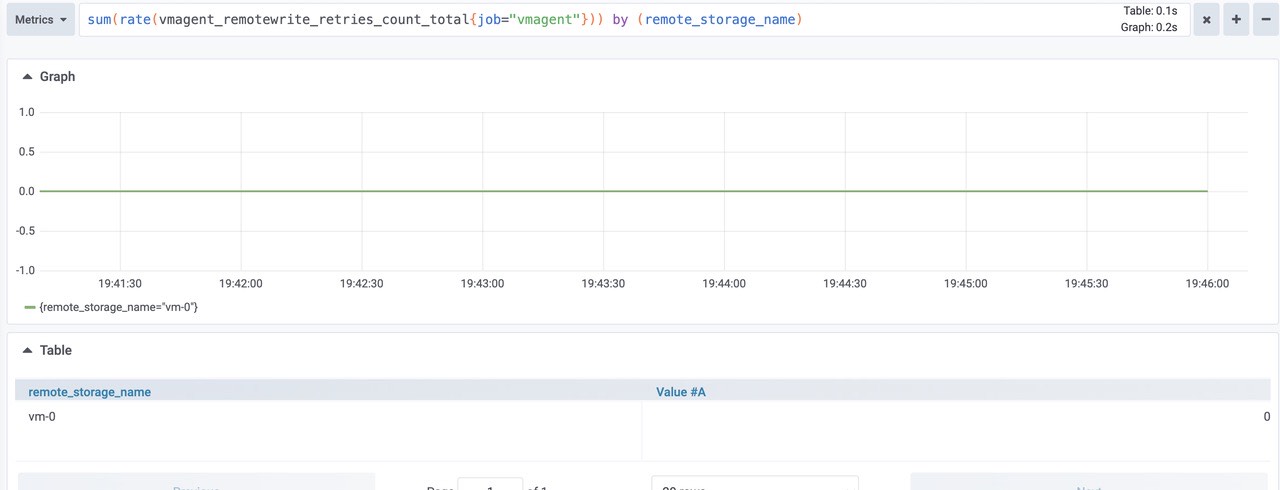
由图可知为0,正常。vmagent 端尚未发送到远程存储的挂起数据量。如果图形增长,则远程存储无法跟上给定的数据摄取率。可以尝试在 chart/values.yaml 中增加 writeConcurrency,如果 prometheus benchmark 的 vmagent 之间存在较高的网络延迟,则可能会有所帮助。
1
sum(vm_persistentqueue_bytes_pending{job="vmagent"}) by (remote_storage_name)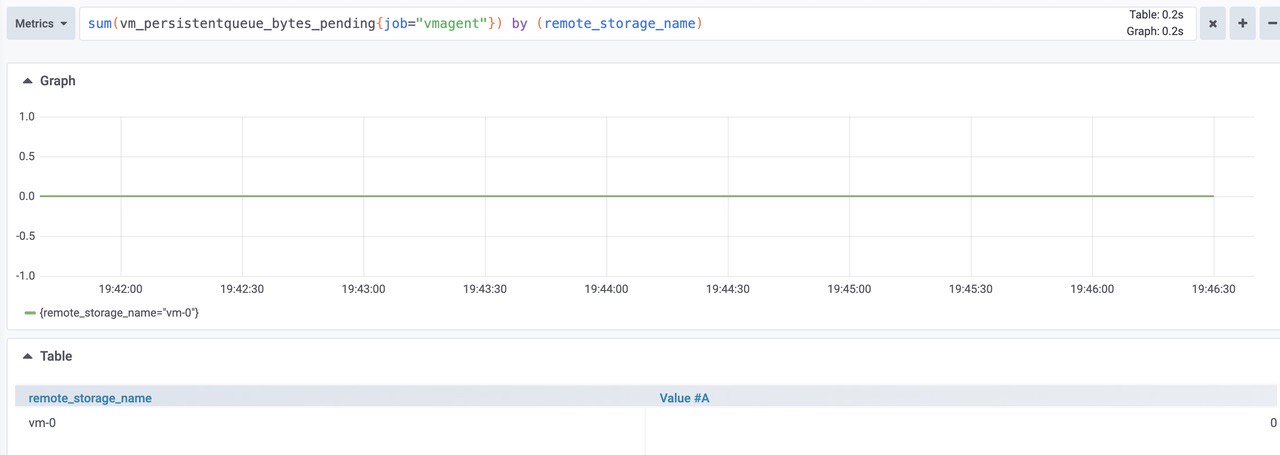
由图可知为0,正常。从 chart/files/alerts.yaml 执行查询时的错误数。如果该值大于零,则远程存储无法处理查询工作负载。在这种情况下,建议检查远程存储日志和 vmalert 日志。
1
sum(rate(vmalert_execution_errors_total{job="vmalert"})) by (remote_storage_name)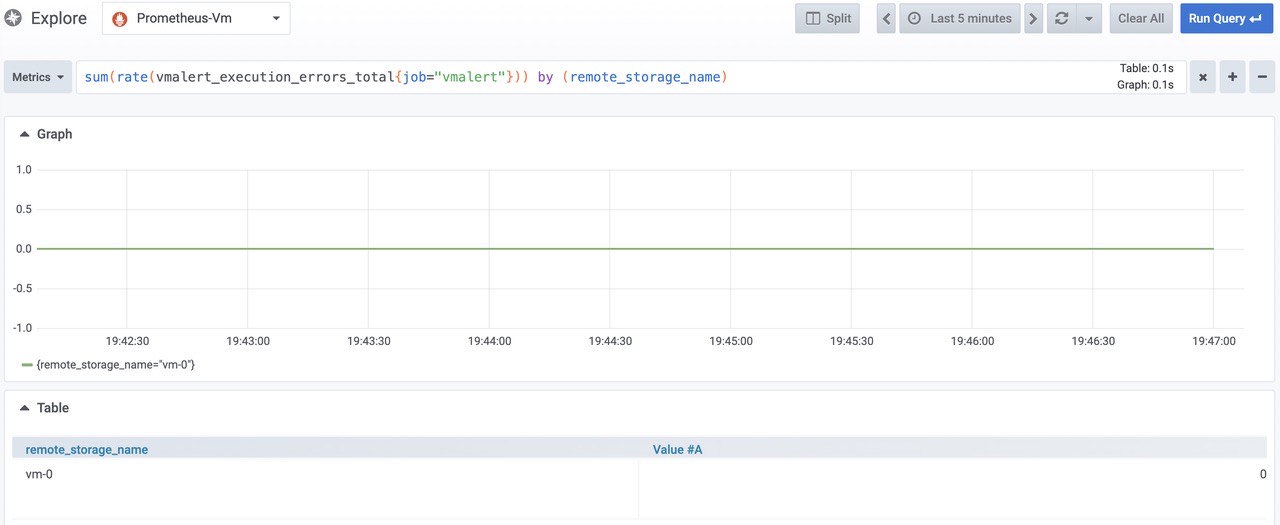
由图可知为0,正常。
总结
3000 Target,450k sample/ sec 的情况下,插入到victoriametrics远程存储完全正常。
4k Target
压测样本配置
- targetsCount 设置为4000
- scrapeInterval设置为10s
- remoteStorages writeURL: “http://192.168.202.83:7480/insert/0/prometheus/api/v1/write“
- writeConcurrency设置为16,并发写。
获取的速率大约为 600k样本/秒
1 | |
指标观测
可以看到,抓取4000target没有任何错误。

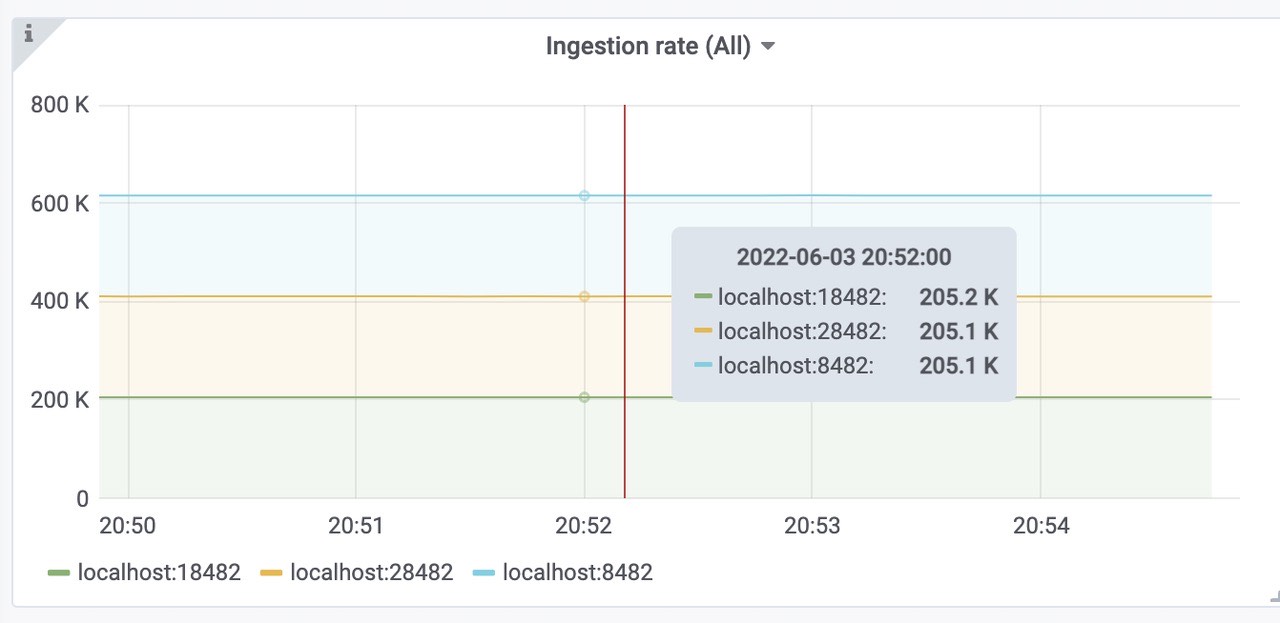
获取样本速率,610k左右,符合预期。
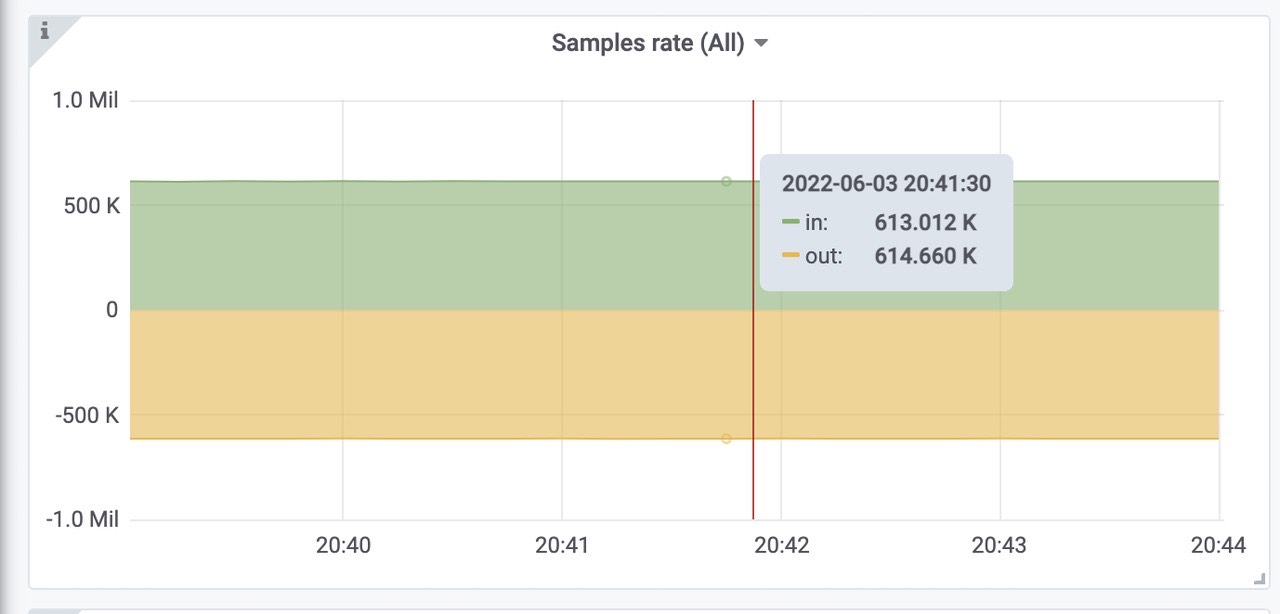
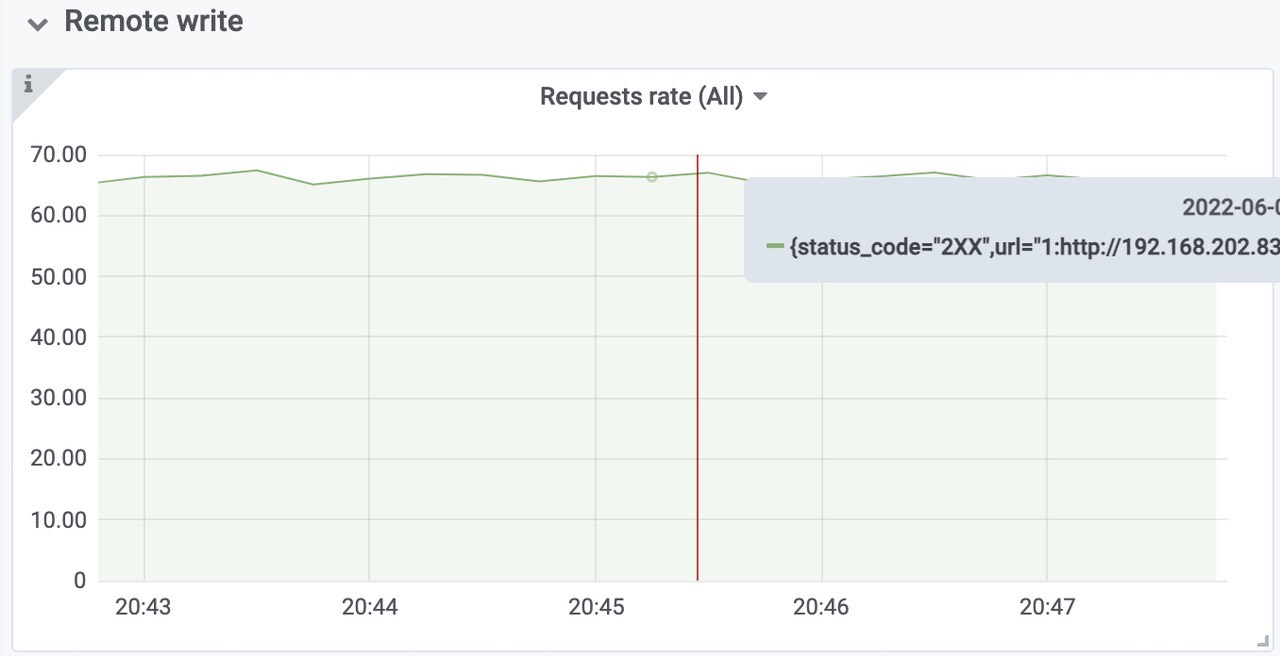
远程写request rate 全部成功
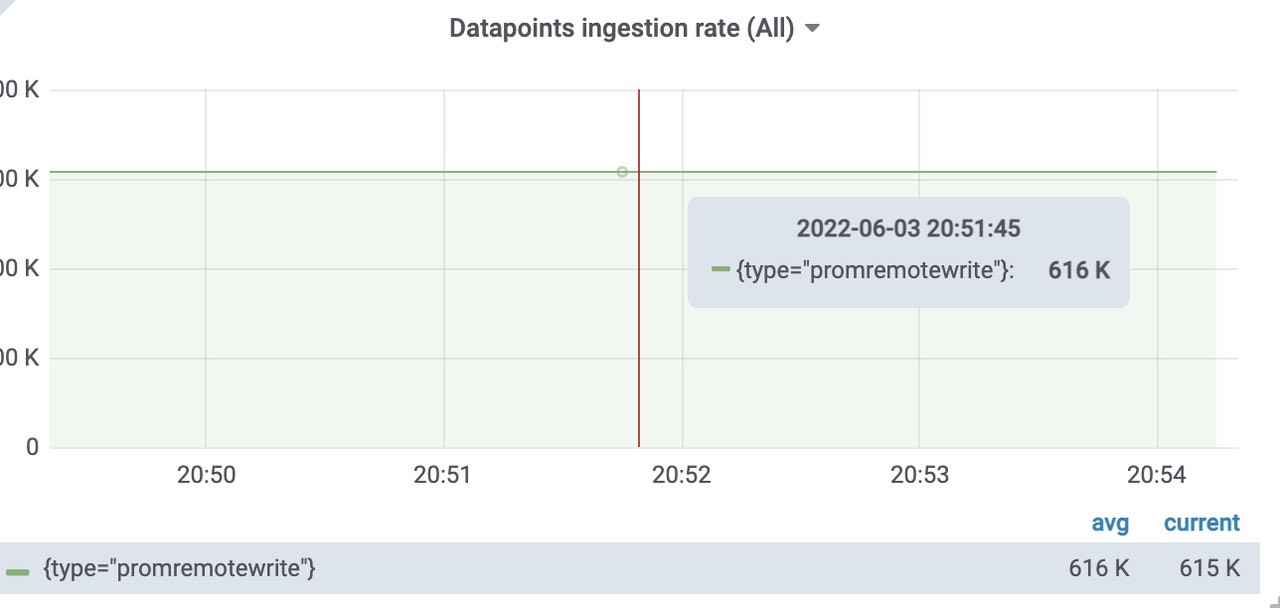
插入到远程存储中的样本数速率为每秒616k。
各组件请求错误率
victoriametrics各组件的日志情况,正常。
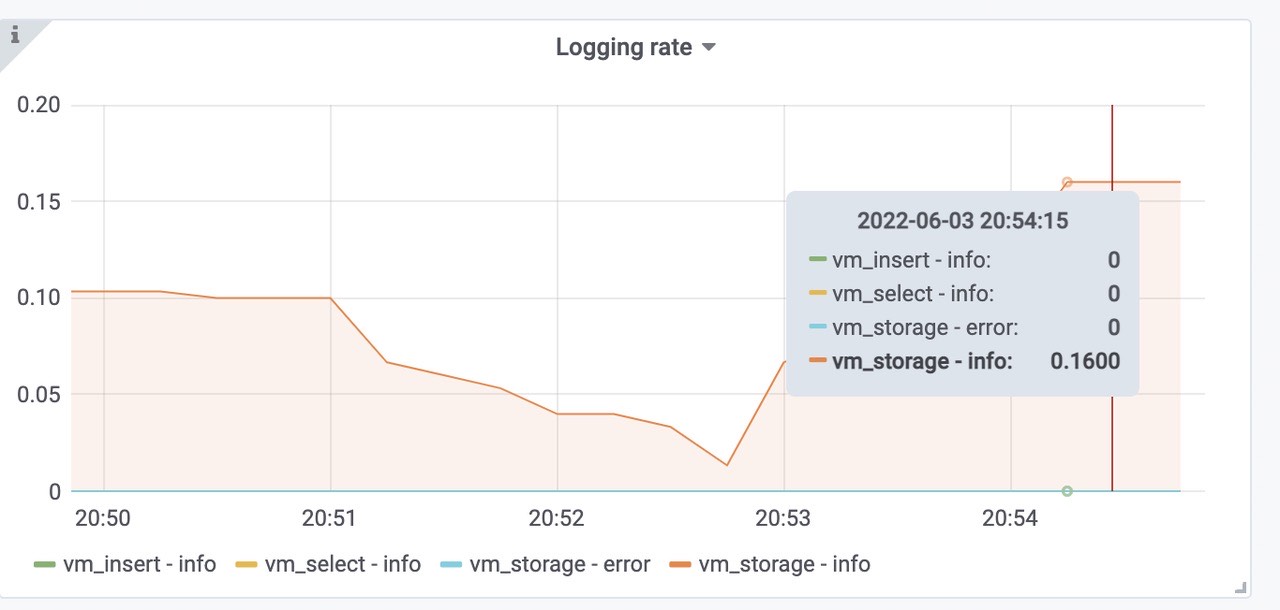
每个远程存储的insert 的 Rows per insert 大概都是10k。
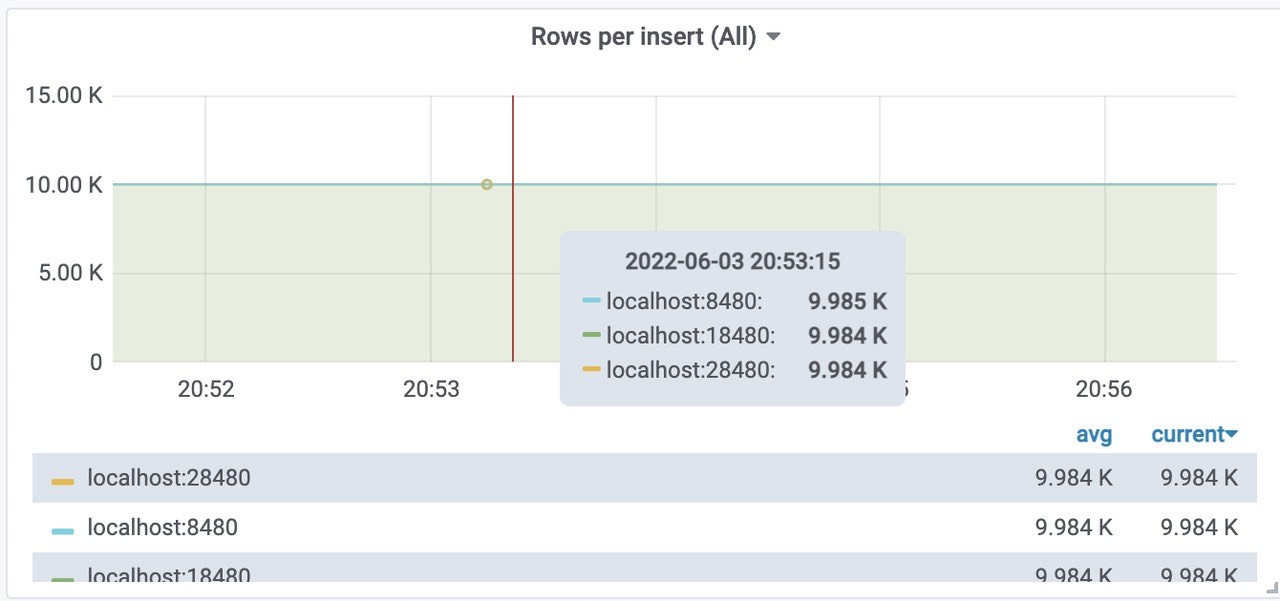
活跃的时间线大概为7Mil左右。
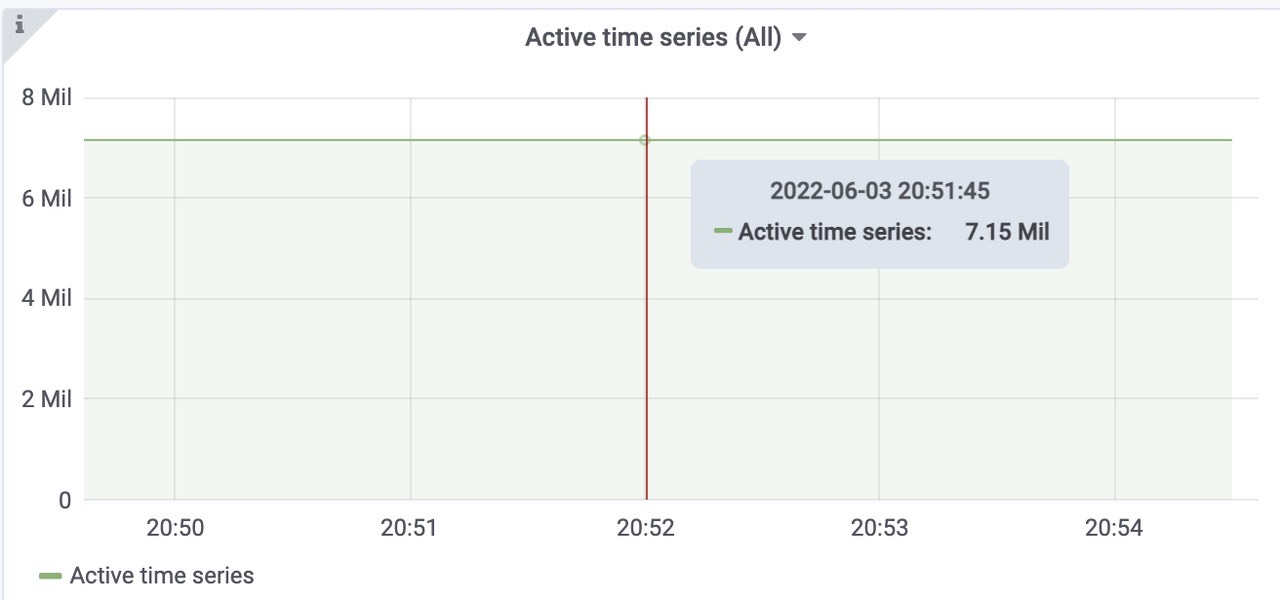
成功插入到vmstorage 中的速率
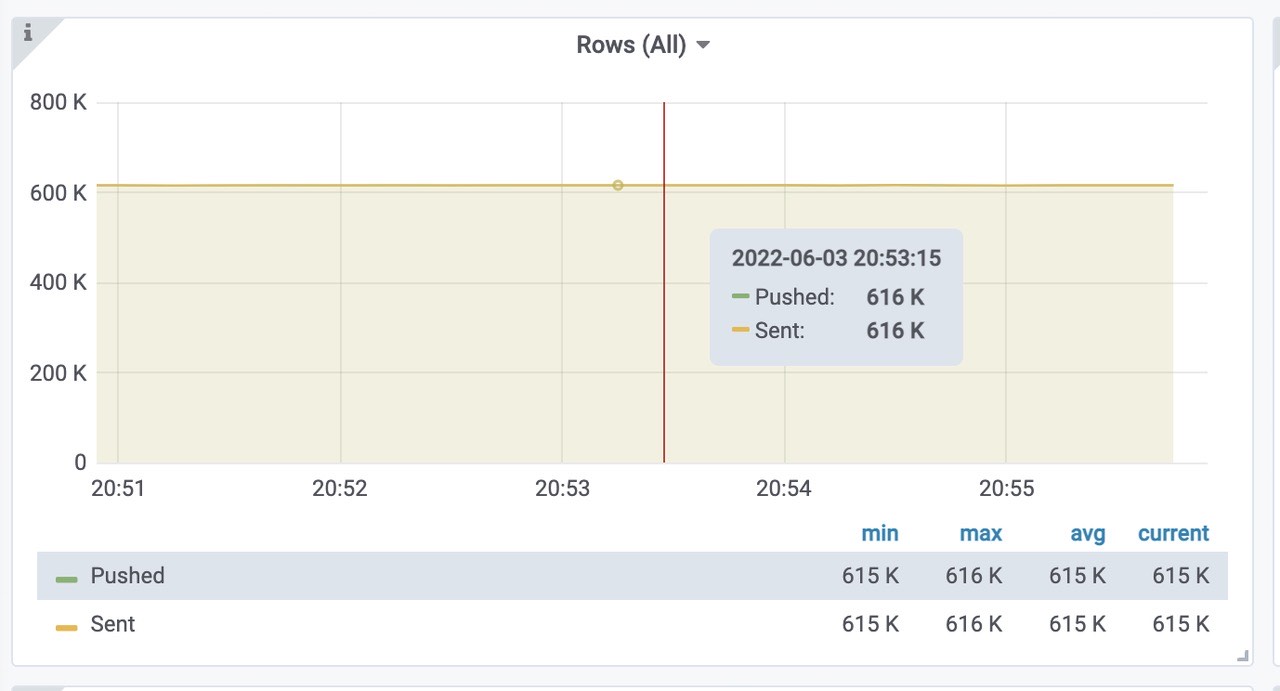
pushed - 在发送之前,将行添加到内部插入器缓冲区中sent - 成功将行传输到存储节点
vmstorage每秒插入的速率,三个storage,平均每个200k
victoriametrics各组件的内存使用情况(vmselect、vminsert、vmstorage)。
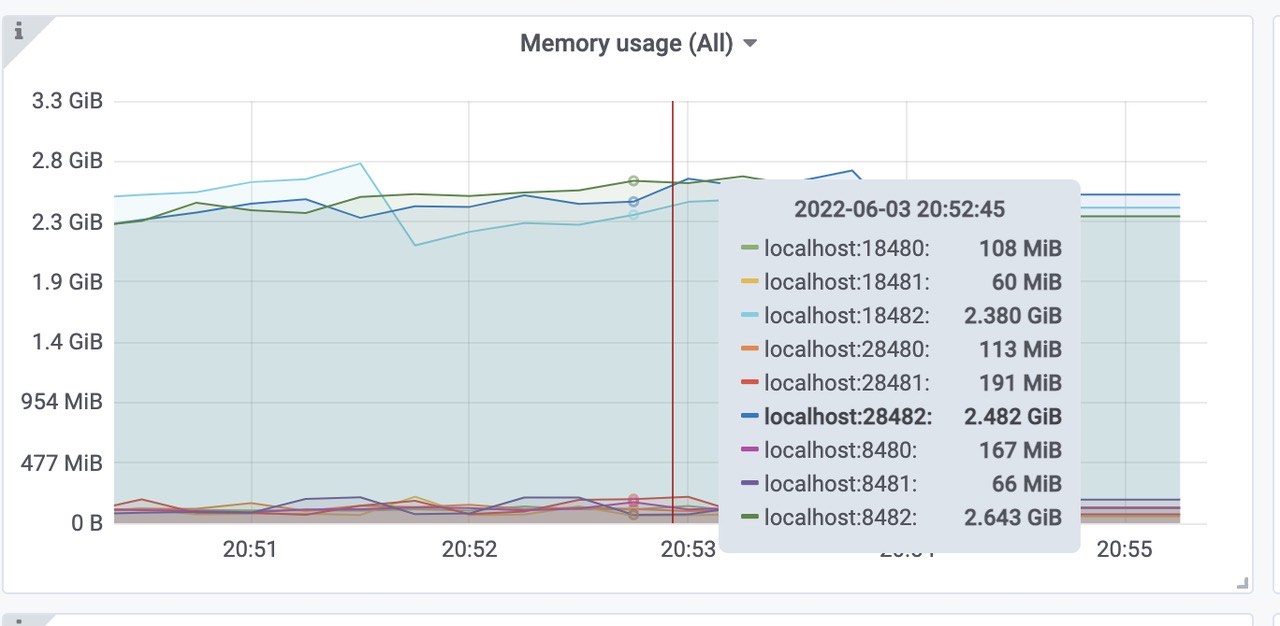
三个vmstorage平均内存使用为2.5Gib左右,总共使用了7.5Gib内存左右。(端口8482、18482、28482)三个vminsert平均使用内存为130Mib左右,总共使用了390Mib内存左右。(端口8480、18480、28480)
三个vmselect平均使用内存为110Mib左右,总共使用了320Mib内存左右。(端口8481、18481、28481)
cpu使用
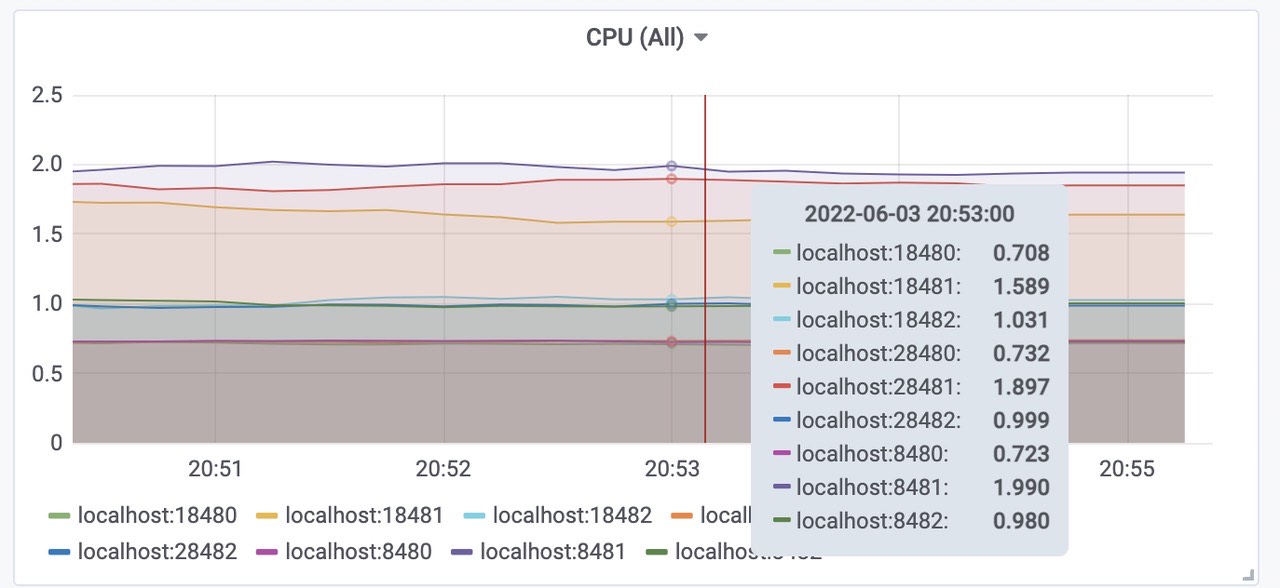
三个vmstorage平均CPU使用为1.7核左右,总共使用了5核左右。(端口8482、18482、28482)三个vminsert平均使用CPU为0.7核左右,总共使用了2.2核左右。(端口8480、18480、28480)
三个vmselect平均使用CPU为1核左右,总共使用了3核内存左右。(端口8481、18481、28481)
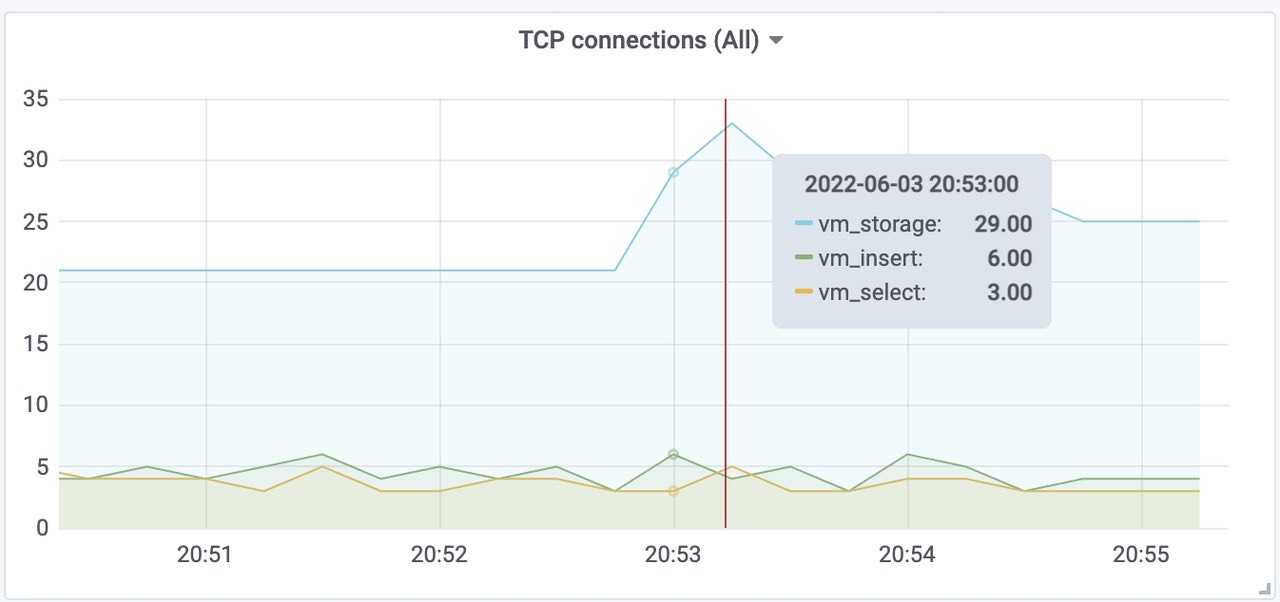
Victoriametrics 各组件tcp连接数
总样本数(包括之前target采集的样本)
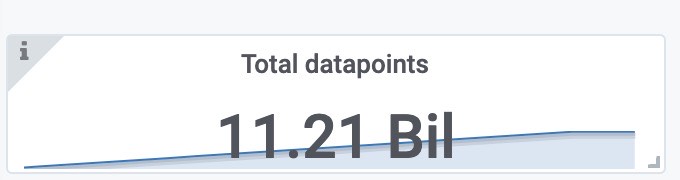
使用磁盘空间(包括之前target采集的样本)
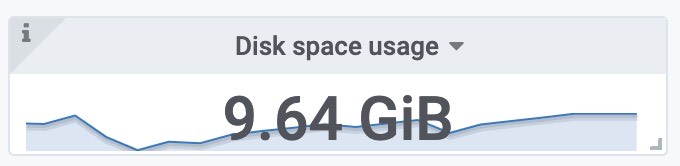
每个样本的大小
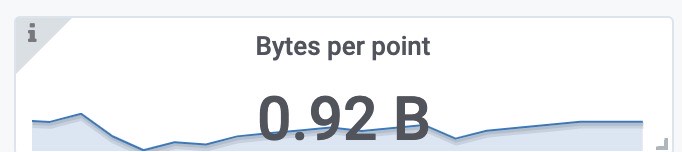
索引文件大小
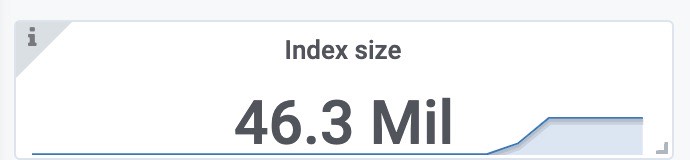
压力位观测
数据摄取率。
1
sum(rate(vm_promscrape_scraped_samples_sum{job="vmagent"})) by (remote_storage_name)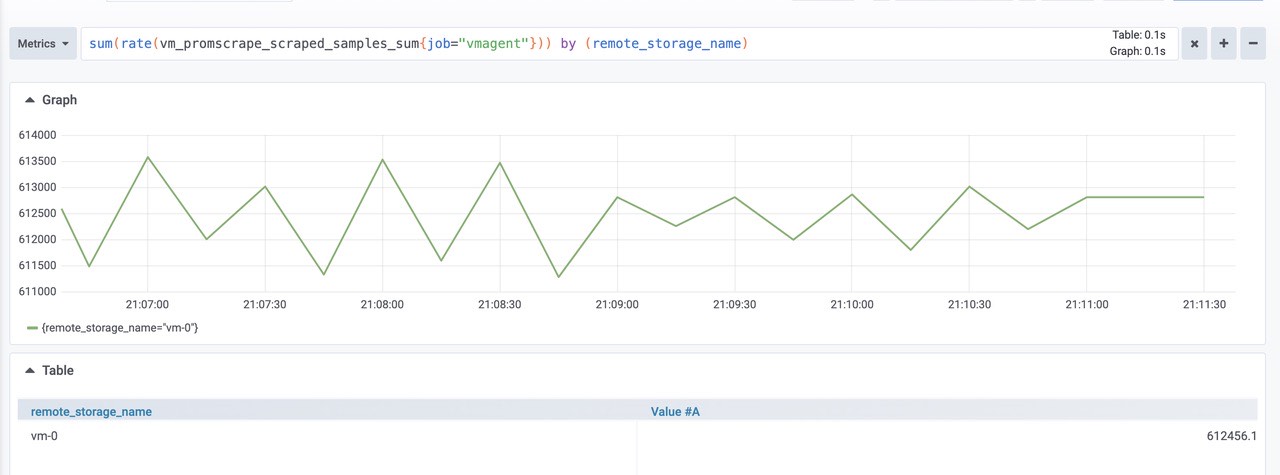
由图可知:大概是610k左右将数据包发送到配置的远程存储时丢弃的数据包数。如果该值大于零,则远程存储拒绝接受传入的数据。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_packets_dropped_total{job="vmagent"})) by (remote_storage_name)
由图可知:丢弃数据包为0,正常。将数据发送到远程存储时的重试次数。如果该值大于零,那么这表明远程存储无法处理工作负载。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_retries_count_total{job="vmagent"})) by (remote_storage_name)
由图可知为0,正常。vmagent 端尚未发送到远程存储的挂起数据量。如果图形增长,则远程存储无法跟上给定的数据摄取率。可以尝试在 chart/values.yaml 中增加 writeConcurrency,如果 prometheus benchmark 的 vmagent 之间存在较高的网络延迟,则可能会有所帮助。
1
sum(vm_persistentqueue_bytes_pending{job="vmagent"}) by (remote_storage_name)
由图可知为0,正常。从 chart/files/alerts.yaml 执行查询时的错误数。如果该值大于零,则远程存储无法处理查询工作负载。在这种情况下,建议检查远程存储日志和 vmalert 日志。
1
sum(rate(vmalert_execution_errors_total{job="vmalert"})) by (remote_storage_name)
由图可知为0,正常。
总结
4000 Target,610k sample/ sec 的情况下,插入到victoriametrics远程存储完全正常。
6k Target
压测样本配置
- targetsCount 设置为6000
- scrapeInterval设置为10s
- remoteStorages writeURL: “http://192.168.202.83:7480/insert/0/prometheus/api/v1/write“
- writeConcurrency设置为16,并发写。
获取的速率大约为 900k样本/秒
1 | |
指标观测
可以看到,抓取6000target没有任何错误。
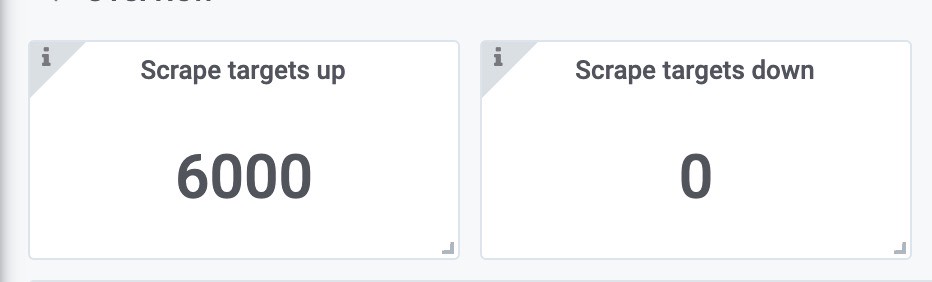
获取样本速率,900k左右,符合预期。
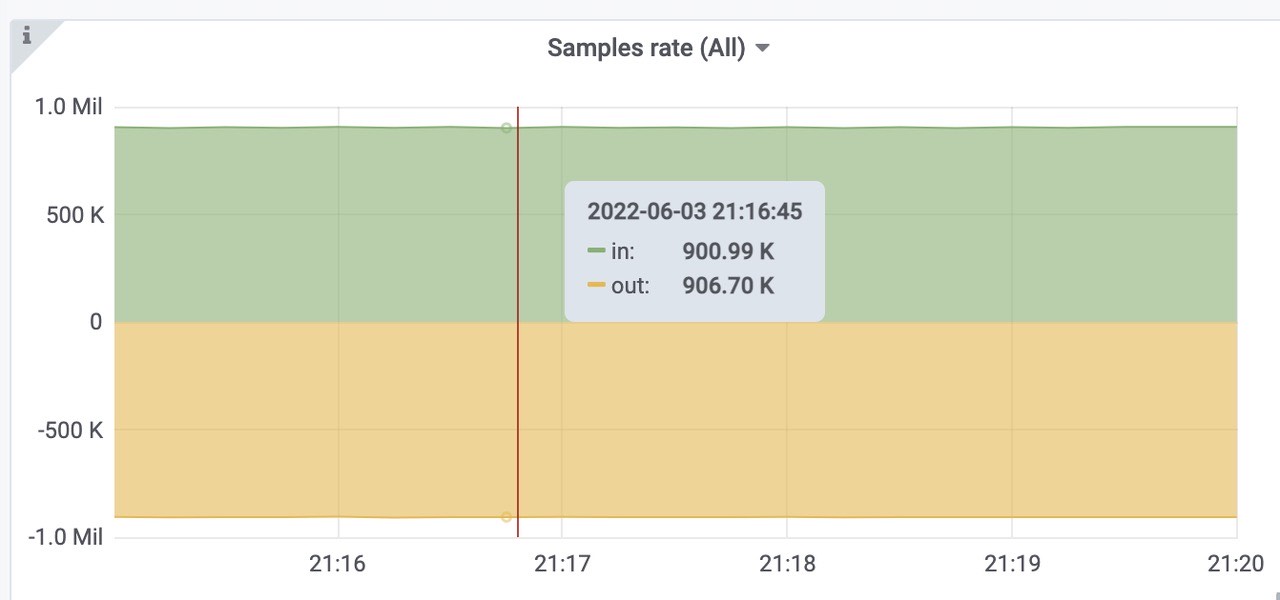
远程写request rate 全部成功
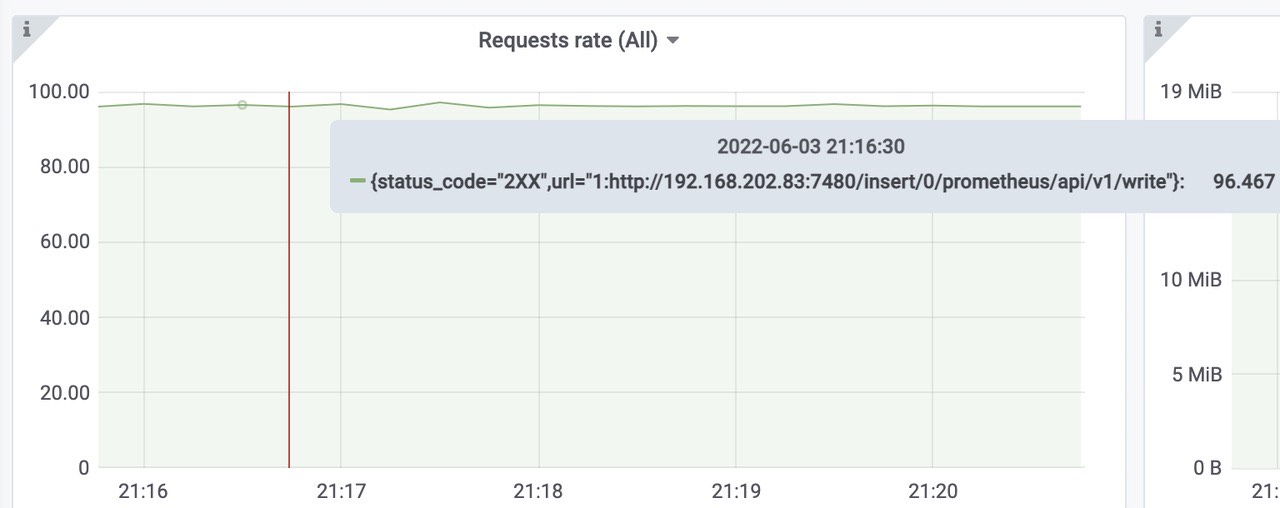
插入到远程存储中的样本数速率为每秒907k。
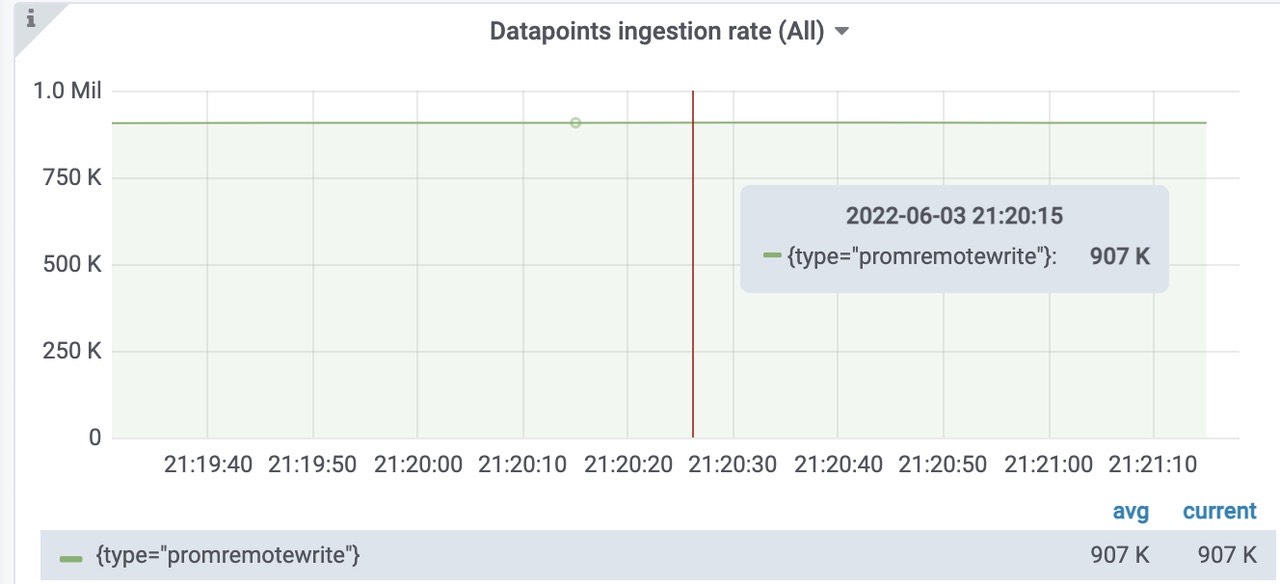
各组件请求错误率
victoriametrics各组件的日志情况,正常。
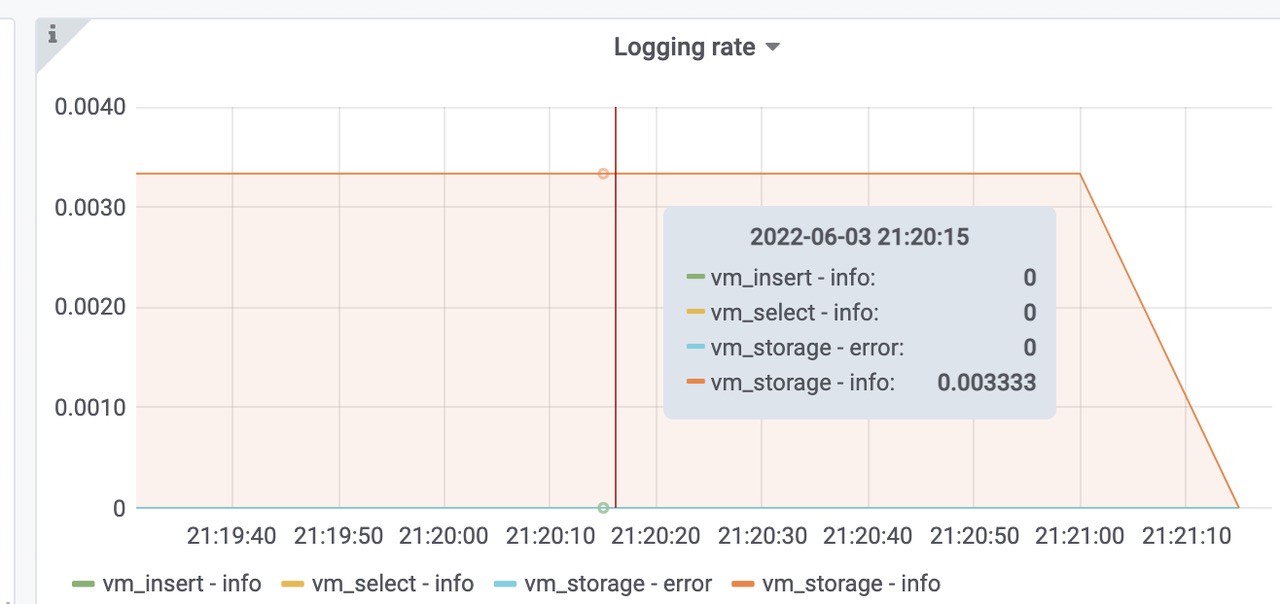
活跃的时间线大概为10Mil左右。
成功插入到vmstorage 中的速率
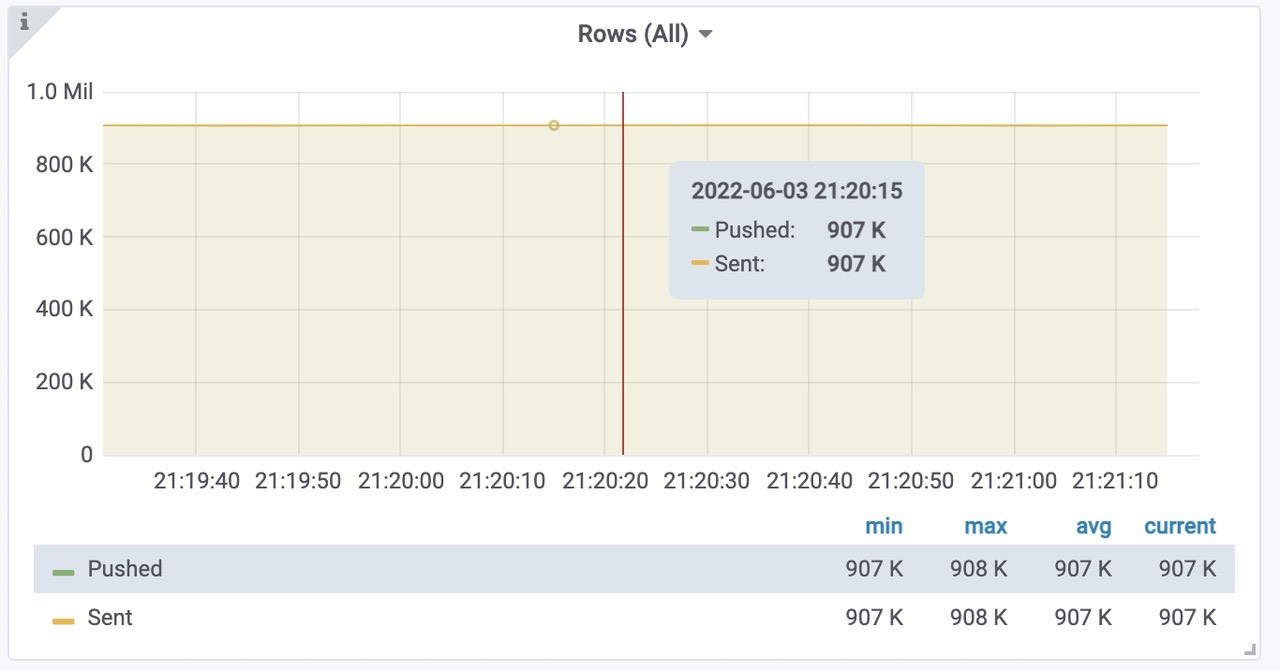
pushed - 在发送之前,将行添加到内部插入器缓冲区中
sent - 成功将行传输到存储节点
vmstorage每秒插入的速率,三个storage,平均每个300k
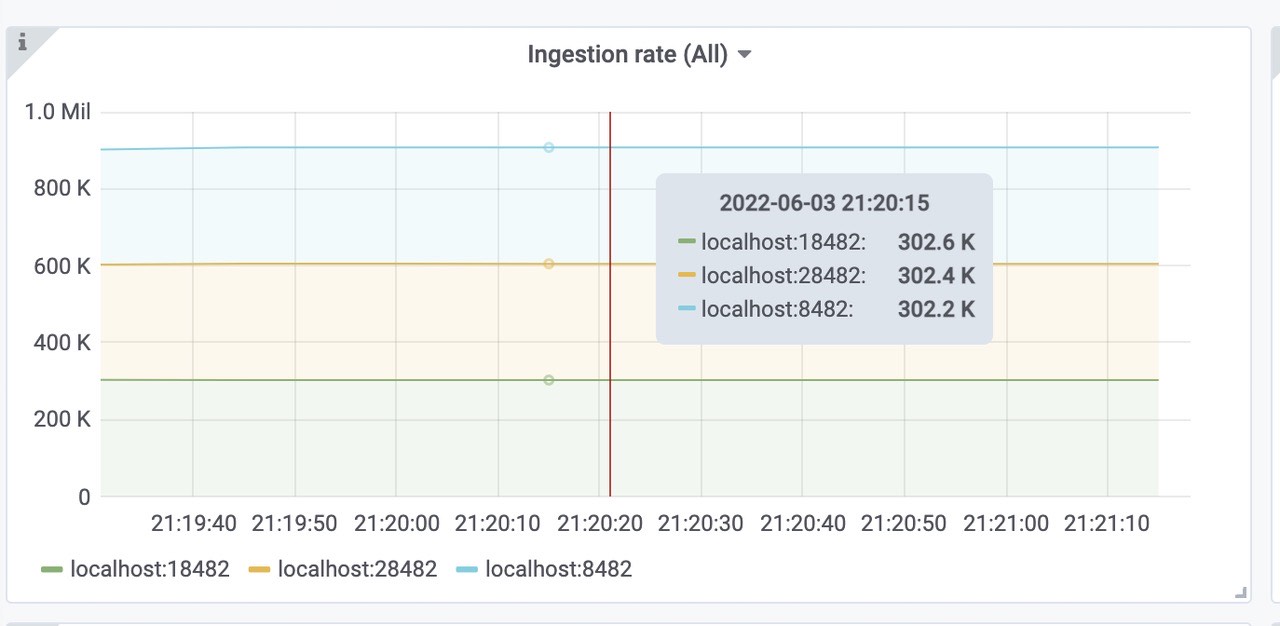
victoriametrics各组件的内存使用情况(vmselect、vminsert、vmstorage)。
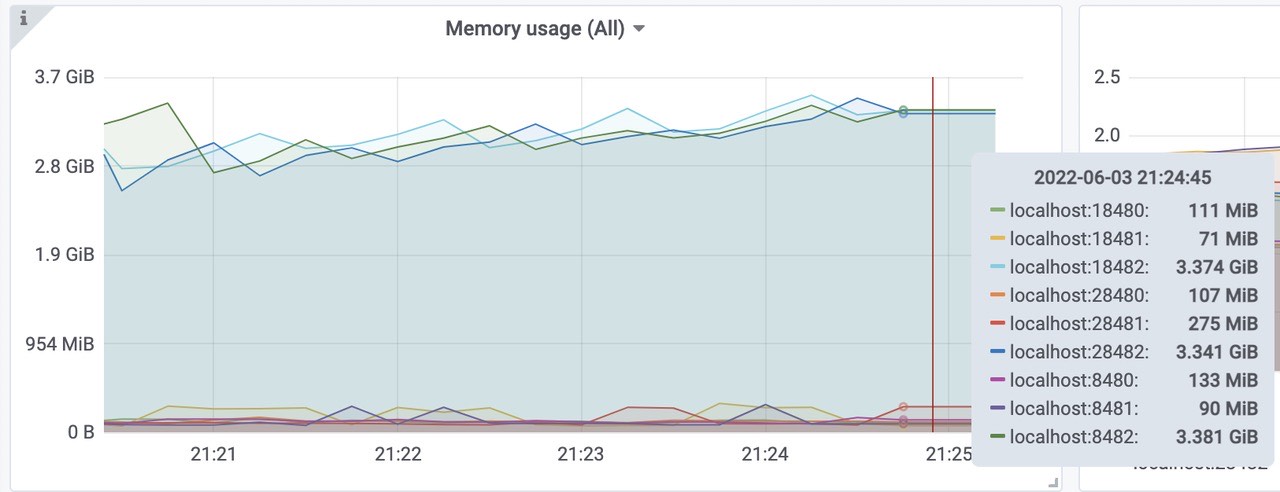
三个vmstorage平均内存使用为3.4Gib左右,总共使用了10Gib内存左右。(端口8482、18482、28482)三个vminsert平均使用内存为120Mib左右,总共使用了360Mib内存左右。(端口8480、18480、28480)
三个vmselect平均使用内存为130Mib左右,总共使用了420Mib内存左右。(端口8481、18481、28481)
cpu使用
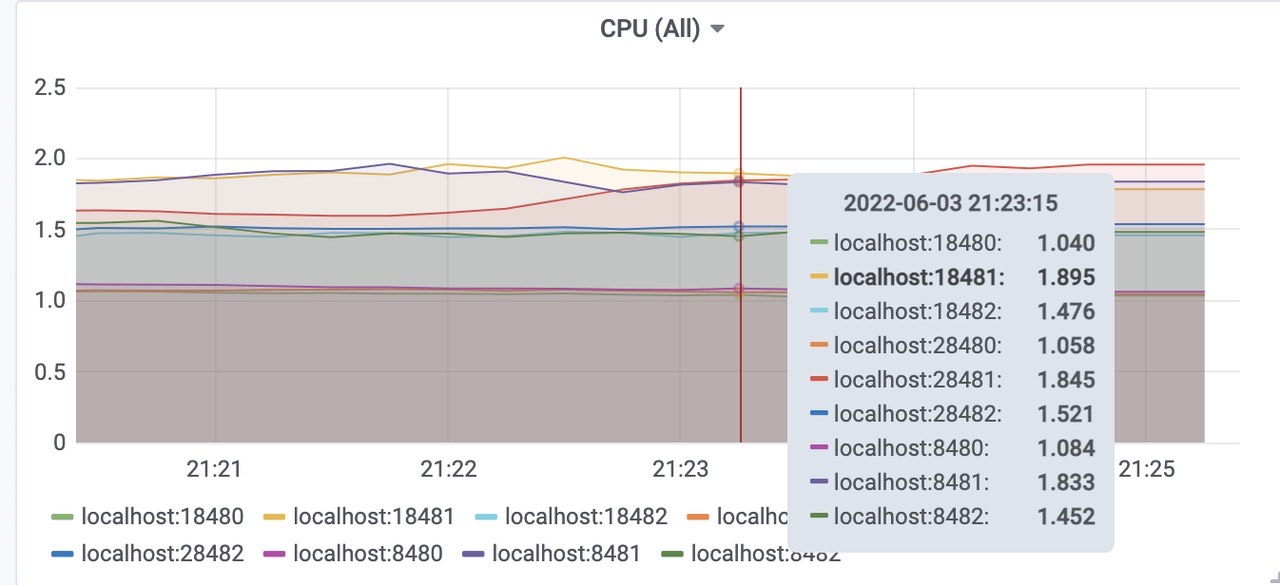
三个vmstorage平均CPU使用为1.5核左右,总共使用了4.5核左右。(端口8482、18482、28482)三个vminsert平均使用CPU为1核左右,总共使用了3核左右。(端口8480、18480、28480)
三个vmselect平均使用CPU为1.8核左右,总共使用了5.4核内存左右。(端口8481、18481、28481)
Victoriametrics 各组件tcp连接数
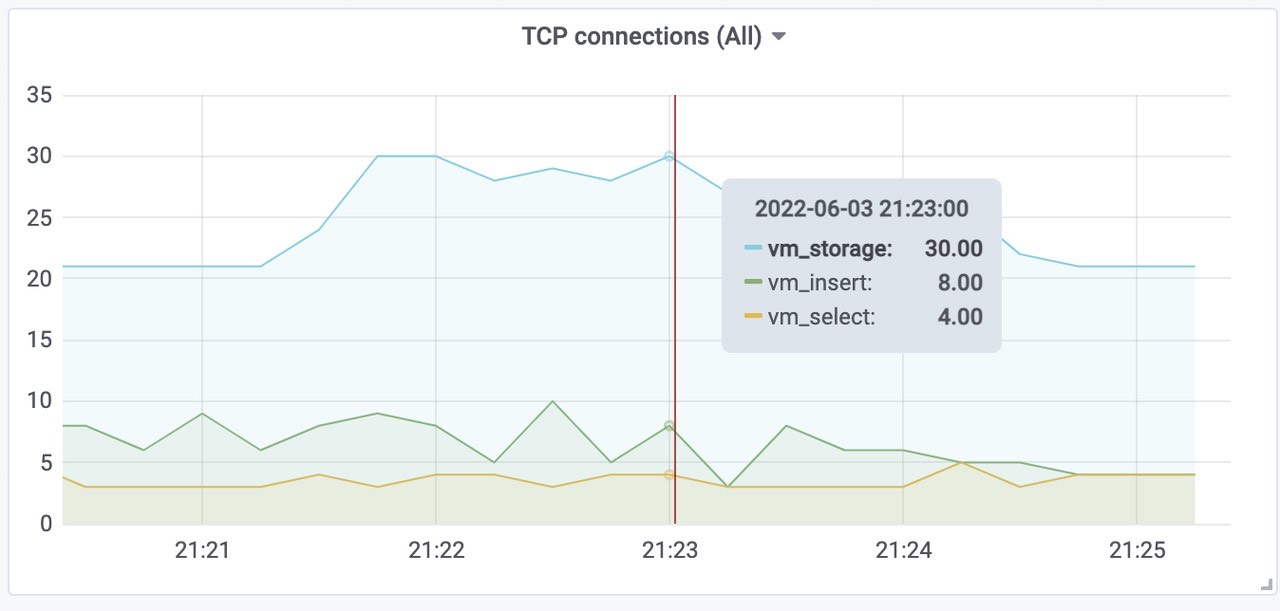
总样本数(包括之前target采集的样本)
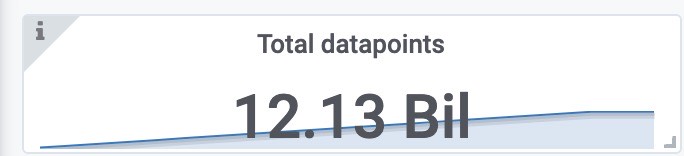
使用磁盘空间(包括之前target采集的样本)
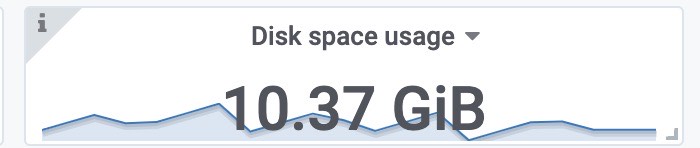
每个样本的大小
索引文件大小
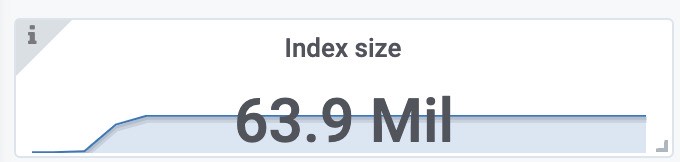
压力位观测
数据摄取率。
1
sum(rate(vm_promscrape_scraped_samples_sum{job="vmagent"})) by (remote_storage_name)
由图可知:大概是900k左右将数据包发送到配置的远程存储时丢弃的数据包数。如果该值大于零,则远程存储拒绝接受传入的数据。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_packets_dropped_total{job="vmagent"})) by (remote_storage_name)
由图可知:丢弃数据包为0,正常。将数据发送到远程存储时的重试次数。如果该值大于零,那么这表明远程存储无法处理工作负载。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_retries_count_total{job="vmagent"})) by (remote_storage_name)
由图可知为0,正常。vmagent 端尚未发送到远程存储的挂起数据量。如果图形增长,则远程存储无法跟上给定的数据摄取率。可以尝试在 chart/values.yaml 中增加 writeConcurrency,如果 prometheus benchmark 的 vmagent 之间存在较高的网络延迟,则可能会有所帮助。
1
sum(vm_persistentqueue_bytes_pending{job="vmagent"}) by (remote_storage_name)
由图可知为0,正常。从 chart/files/alerts.yaml 执行查询时的错误数。如果该值大于零,则远程存储无法处理查询工作负载。在这种情况下,建议检查远程存储日志和 vmalert 日志。
1
sum(rate(vmalert_execution_errors_total{job="vmalert"})) by (remote_storage_name)
由图可知为0,正常。
总结
6000 Target,900k sample/ sec 的情况下,插入到victoriametrics远程存储完全正常。
1w Target
压测样本配置
- targetsCount 设置为10000
- scrapeInterval设置为10s
- remoteStorages writeURL: “http://192.168.202.83:7480/insert/0/prometheus/api/v1/write“
- writeConcurrency设置为30,并发写。(设置16的时候发现有大量的样本来不及发送到远程存储!!!)
获取的速率大约为 1500k样本/秒
1 | |
指标观测
可以看到,抓取10000target没有任何错误。

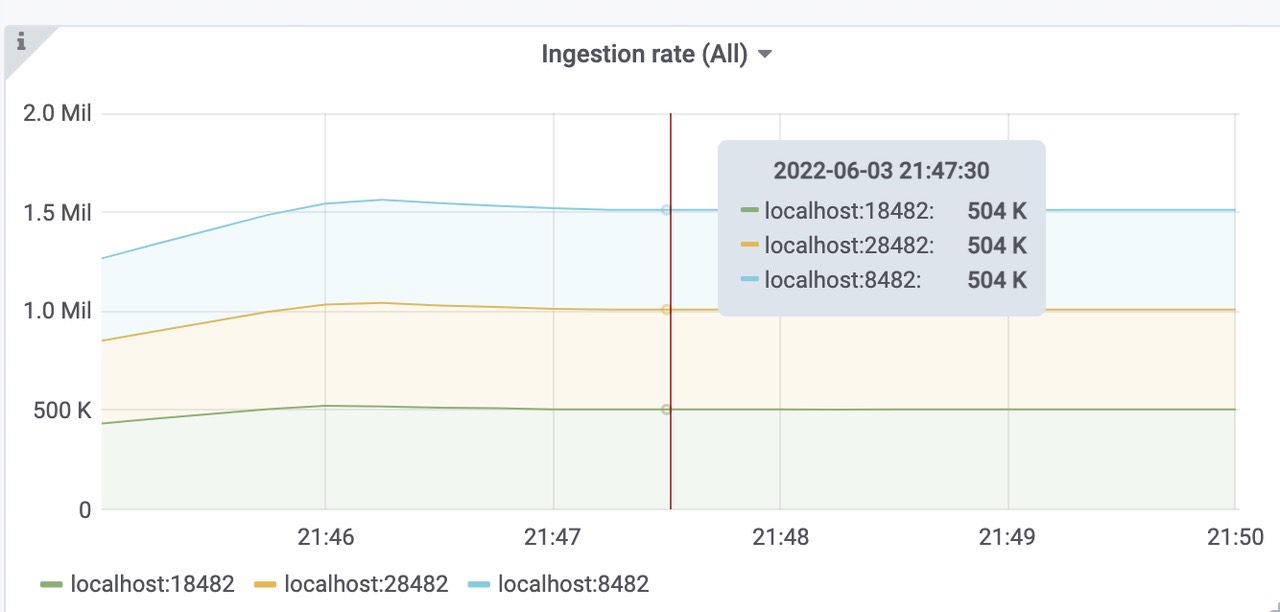
获取样本速率,1.5Mil左右,符合预期。
远程写request rate 全部成功
插入到远程存储中的样本数速率为每秒1.5Mil。
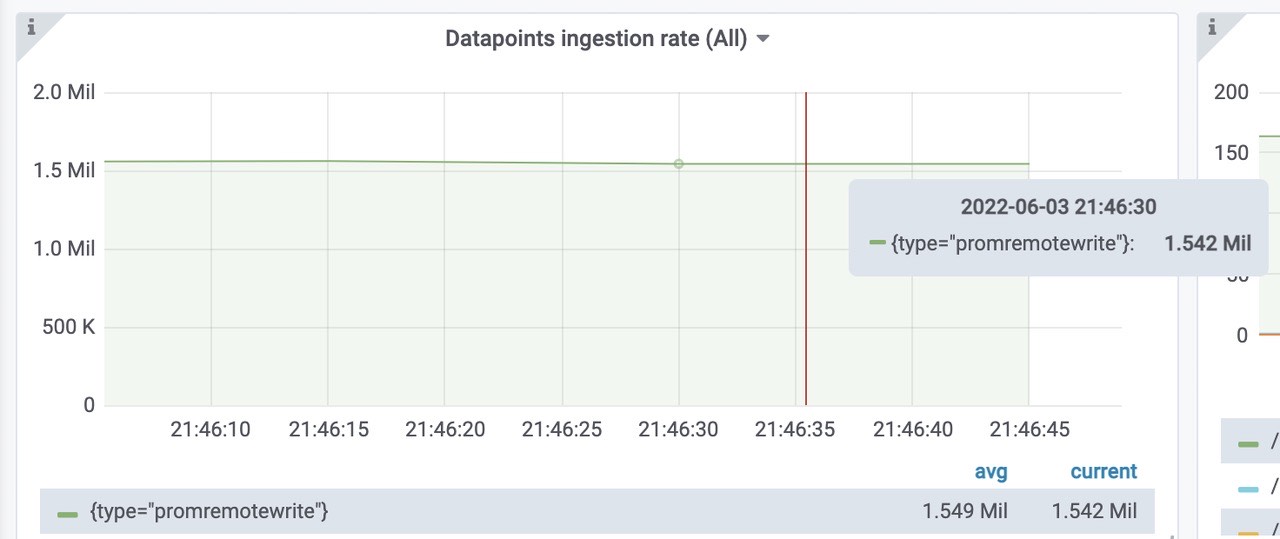
各组件请求错误率
victoriametrics各组件的日志情况,查询会有部分告警,存储部分正常。
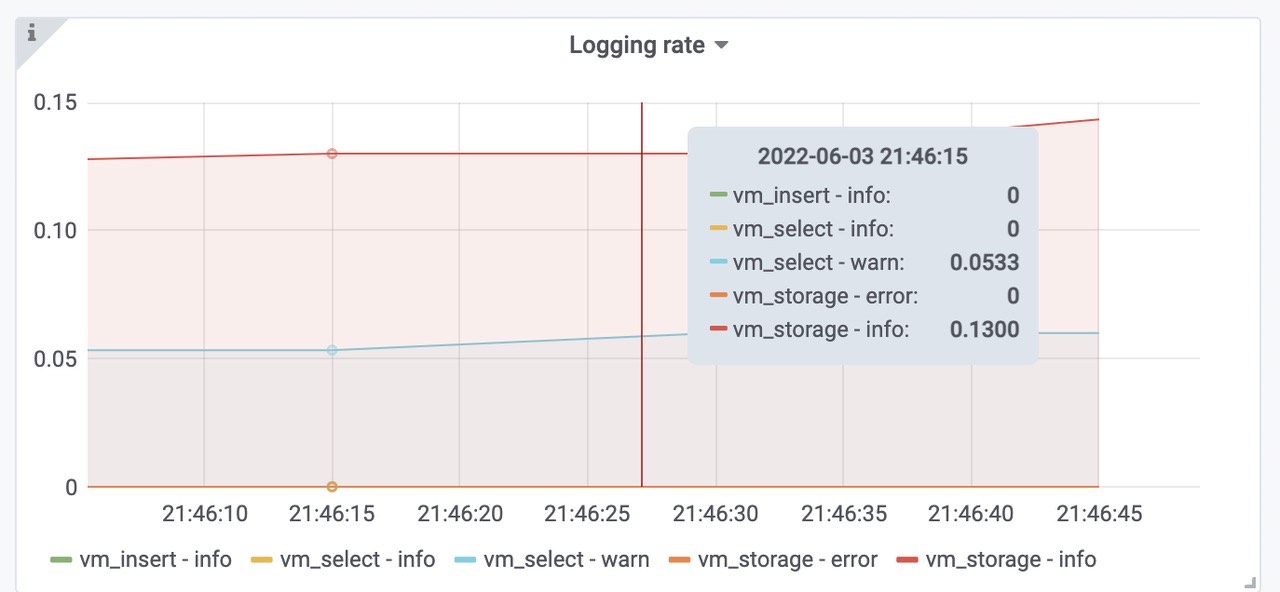
在压测中,也设置了同样的高速率查询压测,就是配置文件中的queryInterval参数。设置的为10s查询,通过查看日志,warn信息主要为慢查询。
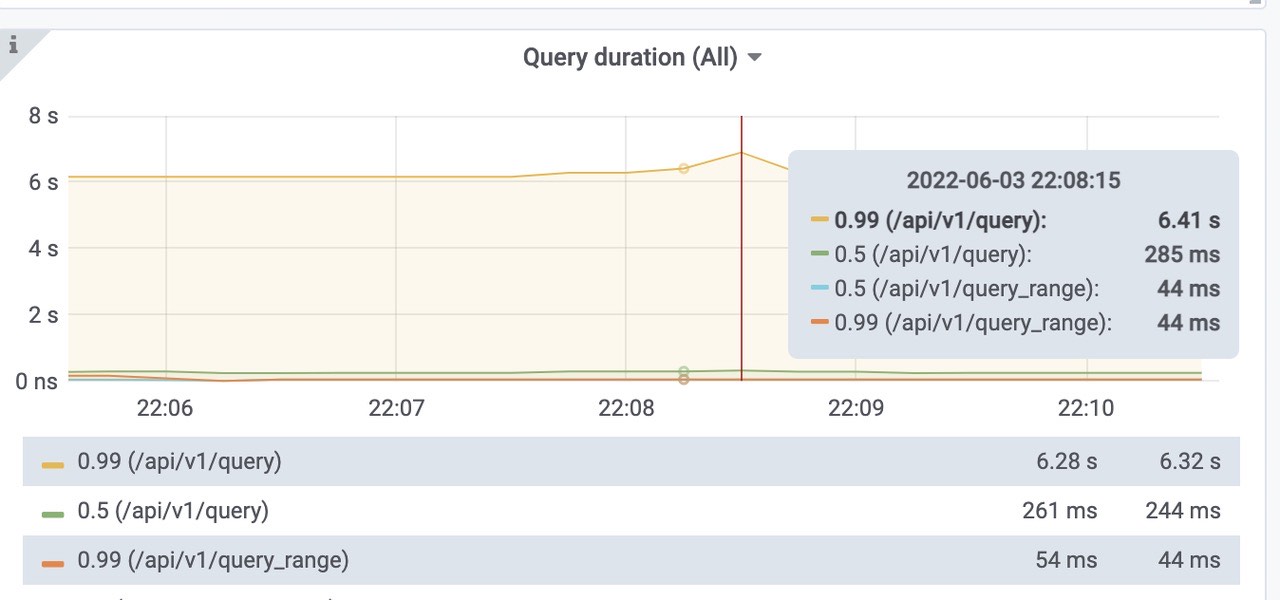
查询延迟:可以看到范围查询的话还是比较快。活跃的时间线大概为18Mil左右。
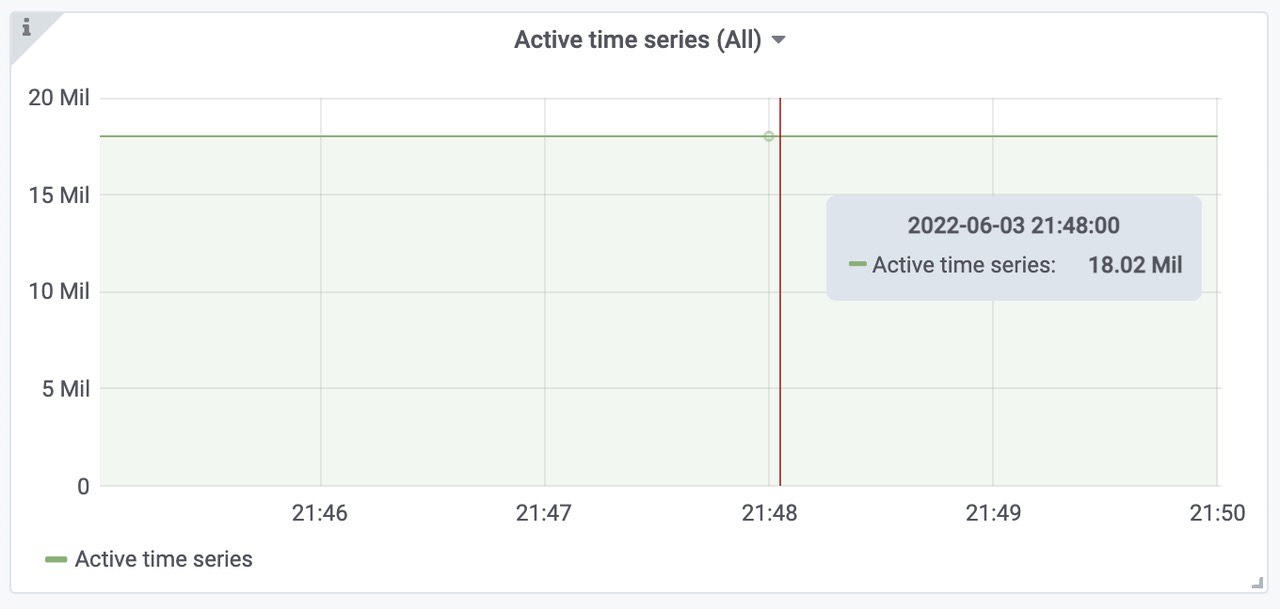
成功插入到vmstorage 中的速率
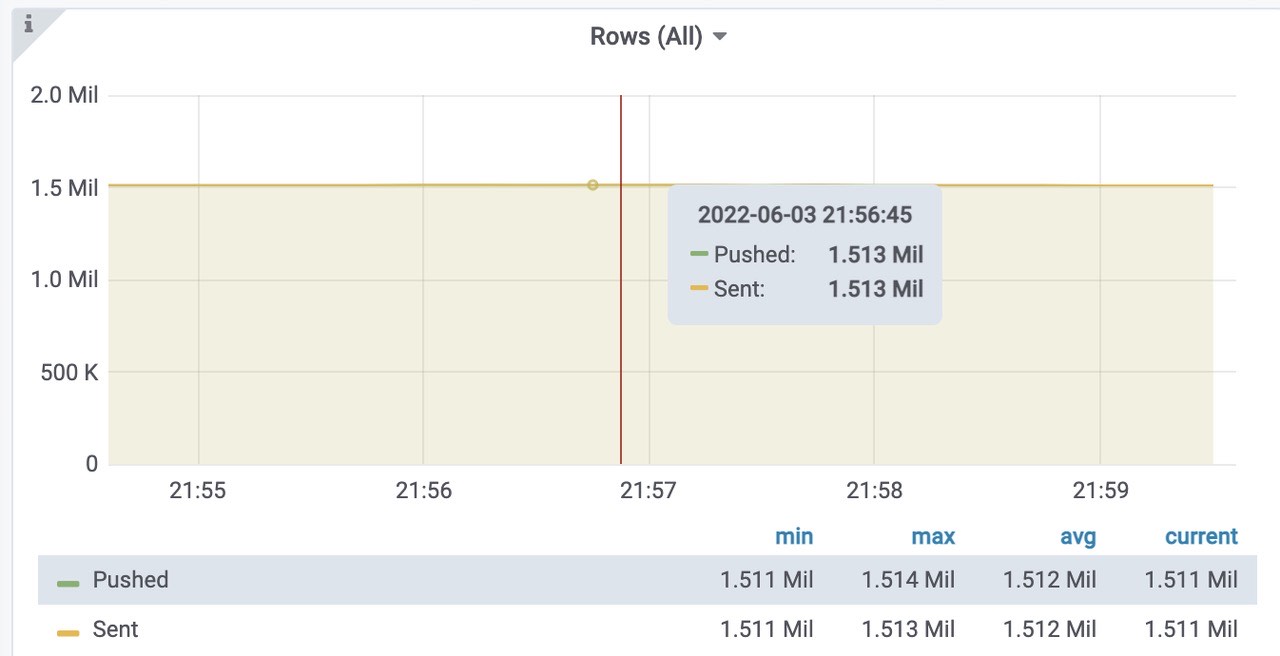
pushed - 在发送之前,将行添加到内部插入器缓冲区中sent - 成功将行传输到存储节点
vmstorage每秒插入的速率,三个storage,平均每个500k
victoriametrics各组件的内存使用情况(vmselect、vminsert、vmstorage)。
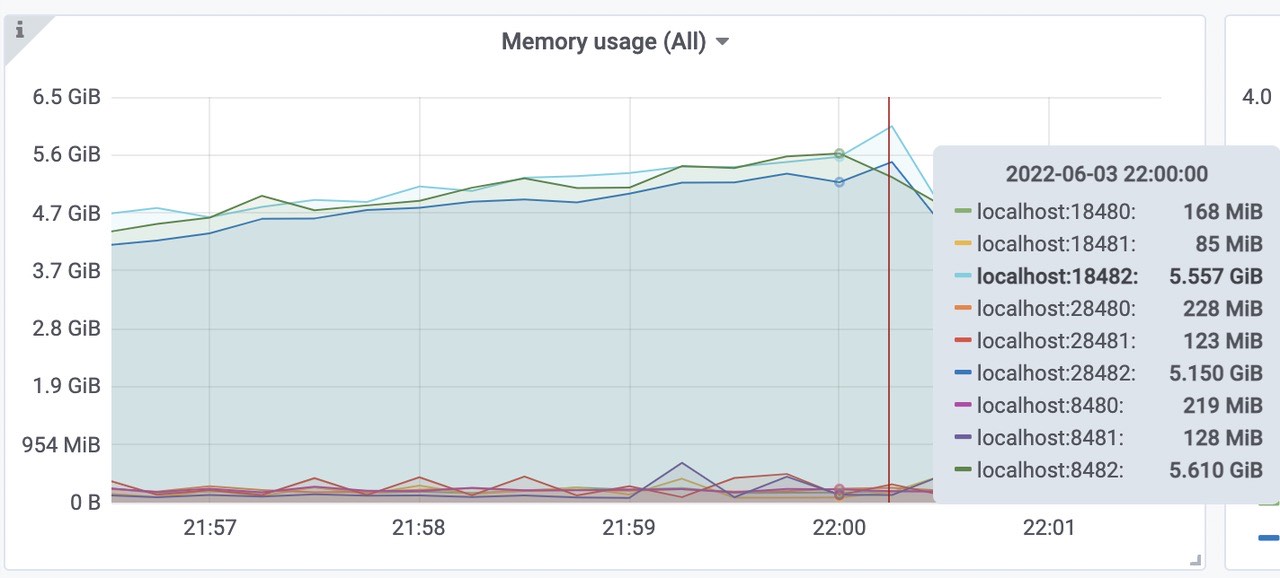
三个vmstorage平均内存使用为5.5Gib左右,总共使用了16Gib内存左右。(端口8482、18482、28482)三个vminsert平均使用内存为205Mib左右,总共使用了615Mib内存左右。(端口8480、18480、28480)
三个vmselect平均使用内存为112Mib左右,总共使用了336Mib内存左右。(端口8481、18481、28481)
cpu使用
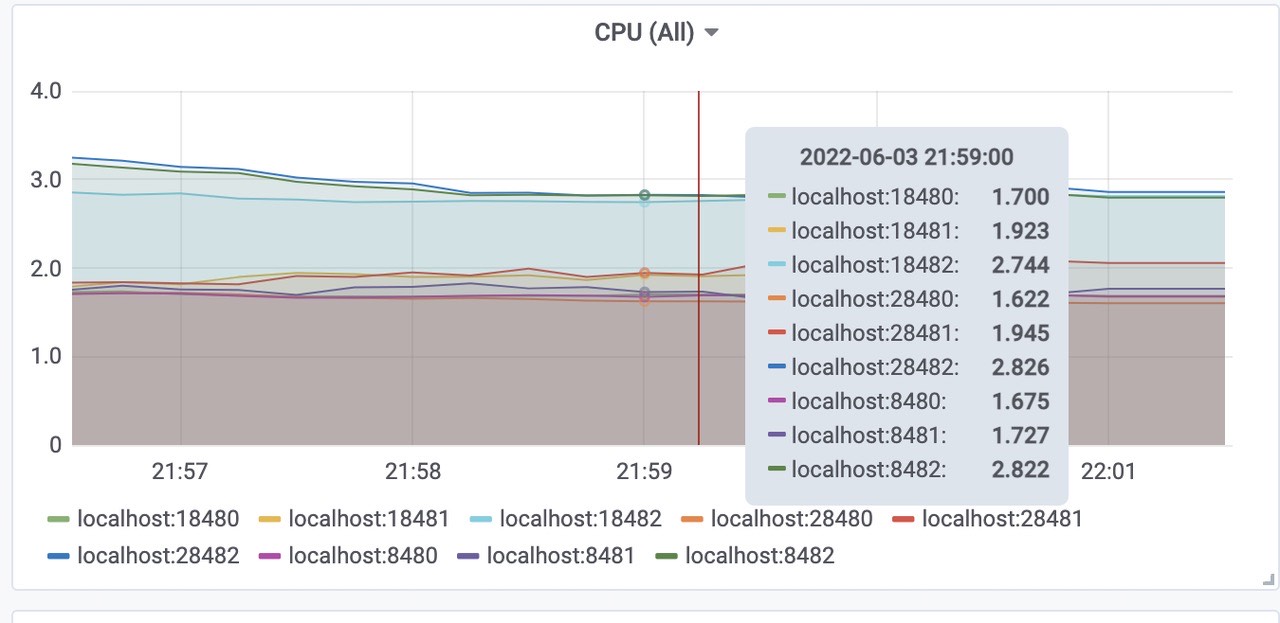
三个vmstorage平均CPU使用为2.8核左右,总共使用了8.4核左右。(端口8482、18482、28482)三个vminsert平均使用CPU为1.7核左右,总共使用了5.1核左右。(端口8480、18480、28480)
三个vmselect平均使用CPU为1.9核左右,总共使用了5.4核内存左右。(端口8481、18481、28481)
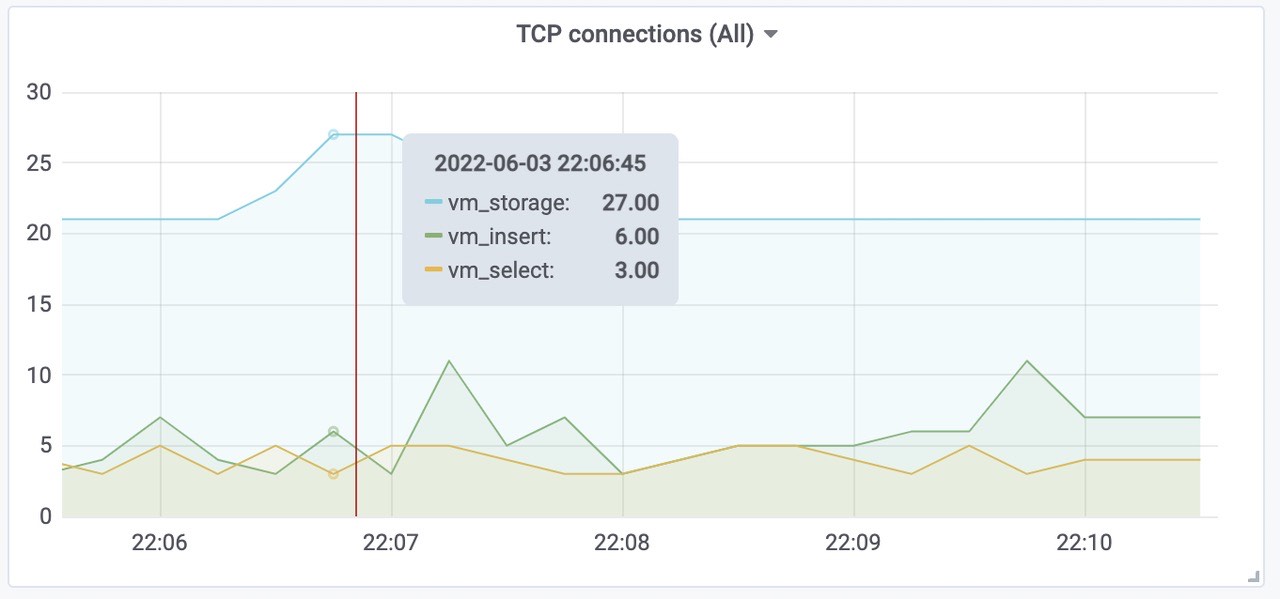
Victoriametrics 各组件tcp连接数
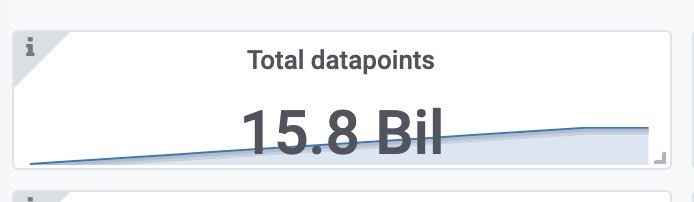
总样本数(包括之前target采集的样本)
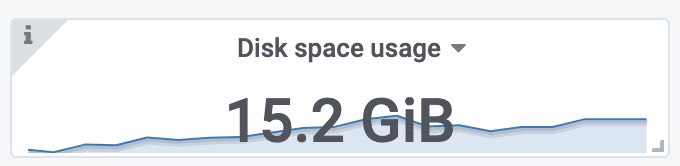
使用磁盘空间(包括之前target采集的样本)
每个样本的大小
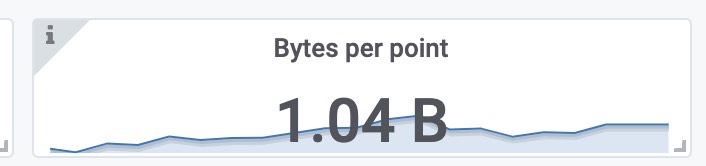
索引文件大小
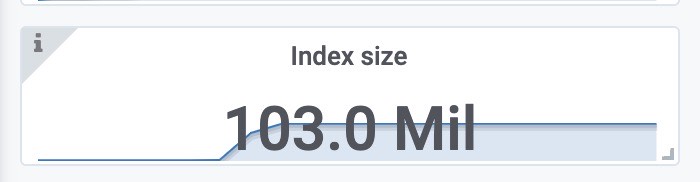
压力位观测
数据摄取率。
1
sum(rate(vm_promscrape_scraped_samples_sum{job="vmagent"})) by (remote_storage_name)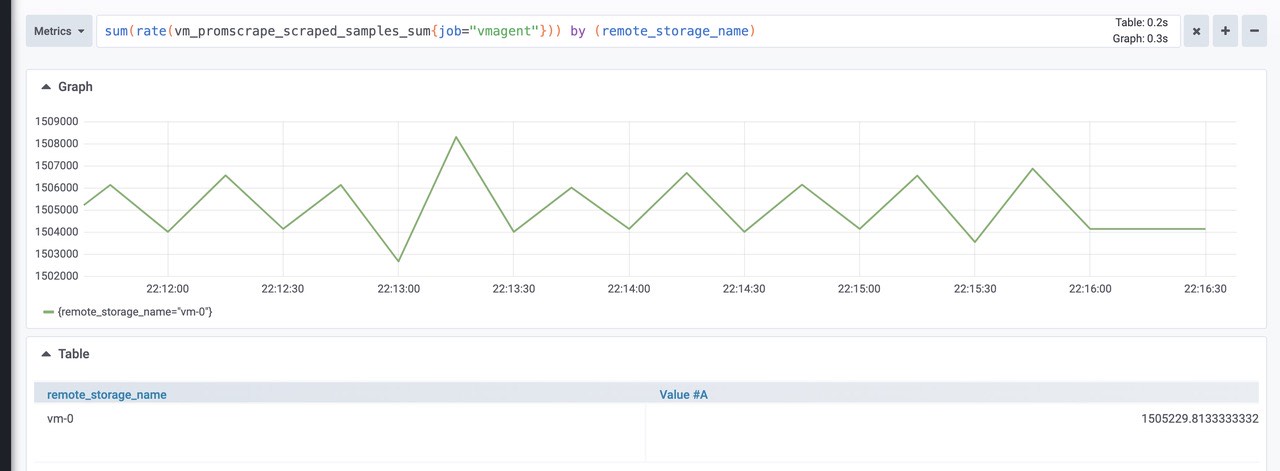
由图可知:大概是1500k左右将数据包发送到配置的远程存储时丢弃的数据包数。如果该值大于零,则远程存储拒绝接受传入的数据。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_packets_dropped_total{job="vmagent"})) by (remote_storage_name)
由图可知:丢弃数据包为0,正常。将数据发送到远程存储时的重试次数。如果该值大于零,那么这表明远程存储无法处理工作负载。在这种情况下,建议检查远程存储日志和 vmagent 日志。
1
sum(rate(vmagent_remotewrite_retries_count_total{job="vmagent"})) by (remote_storage_name)
由图可知为0,正常。vmagent 端尚未发送到远程存储的挂起数据量。如果图形增长,则远程存储无法跟上给定的数据摄取率。可以尝试在 chart/values.yaml 中增加 writeConcurrency,如果 prometheus benchmark 的 vmagent 之间存在较高的网络延迟,则可能会有所帮助。
1
sum(vm_persistentqueue_bytes_pending{job="vmagent"}) by (remote_storage_name)
由图可知为0,正常。从 chart/files/alerts.yaml 执行查询时的错误数。如果该值大于零,则远程存储无法处理查询工作负载。在这种情况下,建议检查远程存储日志和 vmalert 日志。
1
sum(rate(vmalert_execution_errors_total{job="vmalert"})) by (remote_storage_name)
由图可知为0,正常。
总结
10000 Target,1500k sample/ sec 的情况下,插入到victoriametrics远程存储完全正常。
压测总结
- 本次压测了3000、4000、6000、10000 Target情况下,远程存储的各项性能,发现远程存储各项指标都正常。
- 1w Target时,查询的99线会高,查询日志发现是因为有部分慢查询。分析可能是因为带宽被跑满的原因。
- 1w Target时,带宽已经全部跑满了,无法再继续压测。
- 与thanos性能相比,因为暂时无法压测thanos,所以无法得知thanos的性能,但是根据官方介绍,victoriametrics性能更加优越。具体参考Thanos Vs Victoriametrics
- 官方介绍,vm使用的RAM要比thanos 低7倍,存储空间也比Thanos低7倍。