Go map 总结
key为什么是无序的
map在扩容之后,会发生key的搬迁,原来落在同一个bucket会分散在不同的bucket中,所以顺序有可能不同。
另一个是go设计如此,每次遍历的时候都会随机一个bucket编号来开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历。
map不是线程安全的
在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志置位(等于1),则直接 panic。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作。
map删除过程
删除操作底层函数是mapdelete
针对不同的key,会有不同的操作函数。当删除的时候,会检查flag,如果发现flag是1,直接panic。这表明其他协程正在操作这个map。
首先会根据该key计算hash值,看落到那个bucket,同时检查该map是不是正在扩容,如果是在扩容,直接触发一次桶迁移操作。找到对应的key之后,对key和value进行清零操作。最后,就count数减1,并且将对应的tophash置为empty。
map底层实现原理
map的设计也被称为字典,他的任务就是设计一种数据结构来维护一个集合的数据,并且可以同时对数据进行增删改查操作。最主要的数据结构有两种:哈希查找表、搜索树。
哈希查找表用一个哈希函数将key通过一定的算法分配到不同的桶中(bucket,也就是数组中不同的index),这样,开销主要在哈希函数的计算和数组的查找上。
分配桶的时候有两种算法,一种是取模,将key的hash值与桶bucket取模,模是多少就落在哪个桶中。
另一种是位运算,将hash值与桶个数进行位运算,要保证每个bucket都能有元素,就必须保证桶个数为2的N次方。go的map采用的是位运算。
哈希表一般会碰上哈希值碰撞的问题,就是说不同的key被分配到同一个bukcet中。解决的方式有两种,一种是开放地址法,一种是拉链法。go中的map采用的拉链法。
开放地址法,就是当发生碰撞的时候,会在碰撞bucket的后面一次查找新的空位bucket存储。
拉链法指发生碰撞的时候,都存在该bucket中,然后在这个bucket中维护一个链表存储这些key。
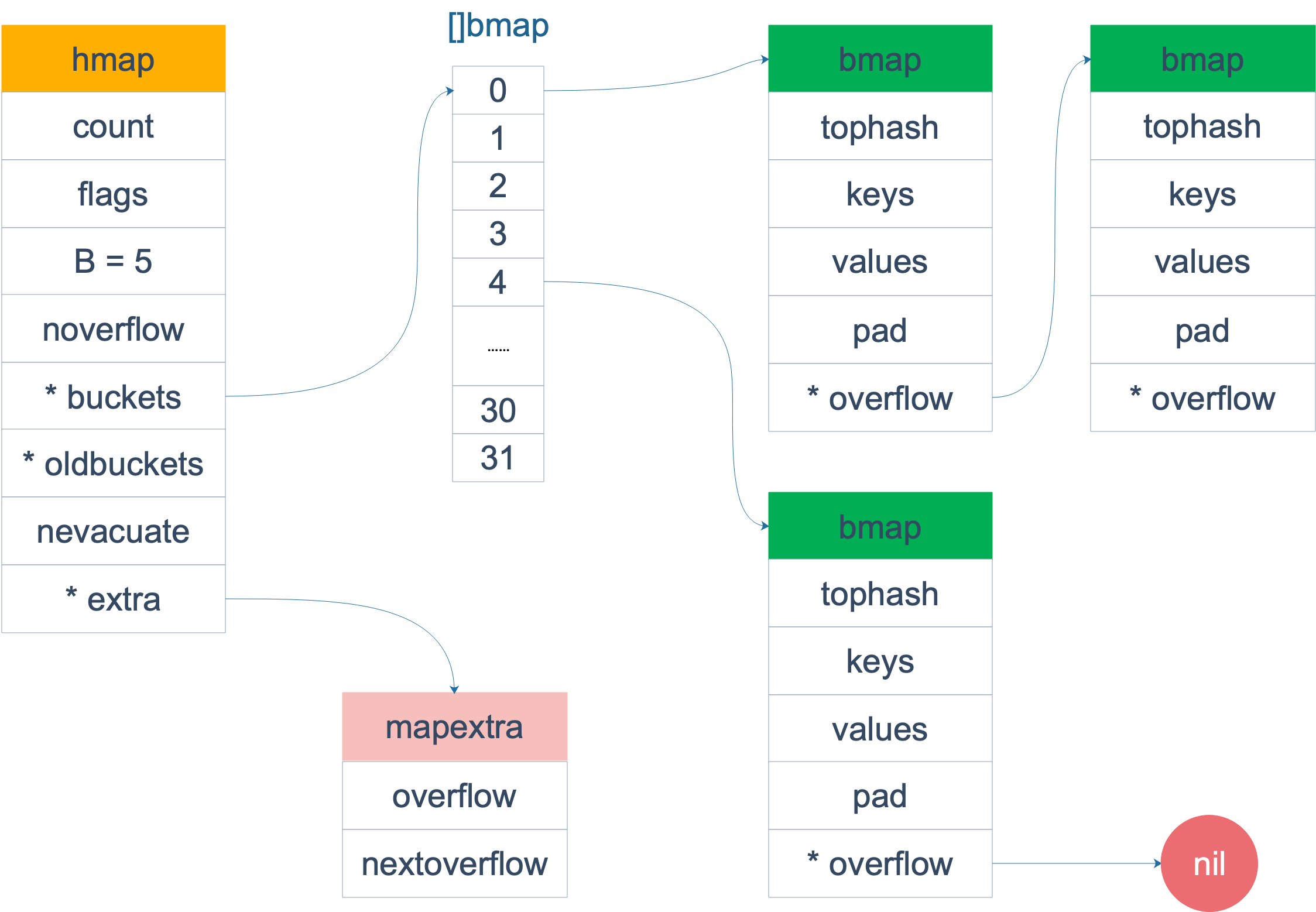
map的源码实现如下:
1 | |
buckets是一个指针,指向一个结构体:
1 | |
上面只是表面的bmap,编译的时候会编译成下面的结构体:
1 | |
bmap就是我们常说的桶,桶里面最多装8个key,这些key之所以会落在同一个桶中,是因为进行hash运算后,hash结果是同一类的。在桶内,又根据计算出来的hash值的高8位来决定key到底落在了桶内的哪个位置。
map总结
key为什么是无序的
map在扩容之后,会发生key的搬迁,原来落在同一个bucket会分散在不同的bucket中,所以顺序有可能不同。
另一个是go设计如此,每次遍历的时候都会随机一个bucket编号来开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历。
map不是线程安全的
在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志置位(等于1),则直接 panic。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作。
map删除过程
删除操作底层函数是mapdelete
针对不同的key,会有不同的操作函数。当删除的时候,会检查flag,如果发现flag是1,直接panic。这表明其他协程正在操作这个map。
首先会根据该key计算hash值,看落到那个bucket,同时检查该map是不是正在扩容,如果是在扩容,直接触发一次桶迁移操作。找到对应的key之后,对key和value进行清零操作。最后,就count数减1,并且将对应的tophash置为empty。
map底层实现原理
map的设计也被称为字典,他的任务就是设计一种数据结构来维护一个集合的数据,并且可以同时对数据进行增删改查操作。最主要的数据结构有两种:哈希查找表、搜索树。
go在程序启动期间,会判断当前cpu是否ase,如果支持,就采用的是ase hash函数。否则使用memhash。
哈希查找表用一个哈希函数将key通过一定的算法分配到不同的桶中(bucket,也就是数组中不同的index),这样,开销主要在哈希函数的计算和数组的查找上。
分配桶的时候有两种算法,一种是取模,将key的hash值与桶bucket取模,模是多少就落在哪个桶中。
另一种是位运算,将hash值与桶个数进行位运算,要保证每个bucket都能有元素,就必须保证桶个数为2的N次方。go的map采用的是位运算。
哈希表一般会碰上哈希值碰撞的问题,就是说不同的key被分配到同一个bukcet中。解决的方式有两种,一种是开放地址法,一种是拉链法。go中的map采用的拉链法。
开放地址法,就是当发生碰撞的时候,会在碰撞bucket的后面一次查找新的空位bucket存储。
拉链法指发生碰撞的时候,都存在该bucket中,然后在这个bucket中维护一个链表存储这些key。
map的源码实现如下:
1 | |
buckets是一个指针,指向一个结构体:
1 | |
上面只是表面的bmap,编译的时候会编译成下面的结构体:
1 | |
bmap就是我们常说的桶,桶里面最多装8个key,这些key之所以会落在同一个桶中,是因为进行hash运算后,hash结果是同一类的。在桶内,又根据计算出来的hash值的高8位来决定key到底落在了桶内的哪个位置。
bmap是存放key/value的地方,其内部布局为:

其中:hob hash就是存储key经过Hash后的高8位,bmap中,key和value并不是以key/value key/value这些的形式存放,而是以key1,key2… value1,value2…这样的方式存放。
map扩容
使用hash表的目的就是为了快速查找到目标key,但是随着想map中添加key,发生碰撞的概率会越来越大,不同key落在同一个桶中的概率也越来越大。bucket中的8个位置也会逐渐被塞满,查找、删除,更新对应的key效率也会越来越慢。最理想的状况是一个bucket中只装一个key。就能达到O(1)的效率,这就是用空间换时间。go语言中一个bucket装载8个key,这同时又是用时间换空间。
当然,这样做要有个度,不然所有key都落入到一个bucket中,直接退化成一个链表,各种操作又变成了O(n),效率又下降下来了,所以map有一个指标,叫装载因子,其计算公式为:
1 | |
在向map中写入新的key的时候,会进行条件检测,当满足以下两个条件的时候,就会触发扩容规则:
- 装载因子超过阈值,在go中,阈值定义的为6.5
- overflow的bucket的数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。
解释:
对于第一条,很好理解,每个bucket只会装载8个key,当装载因子大于6.5的时候表示8个坑位都快装满的了,查找,删除都会变得效率很低下。这个时候进行扩容是变得很有必要了。
对于第二条,其实是对第一条的补充,就是说在装载因子比较小的情况下,各个key比较分散,这时候 map 的查找和插入效率也很低,而第 1 点识别不出来这种情况。表面现象就是计算装载因子的分子比较小,即 map 里元素总数少,但是 bucket 数量多(真实分配的 bucket 数量多,包括大量的 overflow bucket)。造成这种情况可能有不停的插入、删除元素。先插入很多元素,导致创建了很多bucket,但是达不到第一种情况,未触发扩容。之后,再删除元素的总数量,再插入很多元素,导致创建很多overflow。
针对这两种不同的情况,有不同的扩容规则:
装载因子过大的扩容规则
针对装载因子过大,解决的办法很简单,就是直接增加bucket的个数,其规则是直接将B+1,也就是将桶的个数翻倍。注意,这个时候元素都在老的bucket中,还没迁移到新的bucket中来。
overflow数量过多
其实元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
具体做法就是:
由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果有大量的 key/value 需要搬迁,会非常影响性能。因此 Go map 的扩容采取了一种称为“渐进式”地方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。