Go channel 总结
csp
CSP 全称是 “Communicating Sequential Processes”,其主要含义就是说不要通过共享内存来通信,而是通过通信来共享内存。
底层数据结构
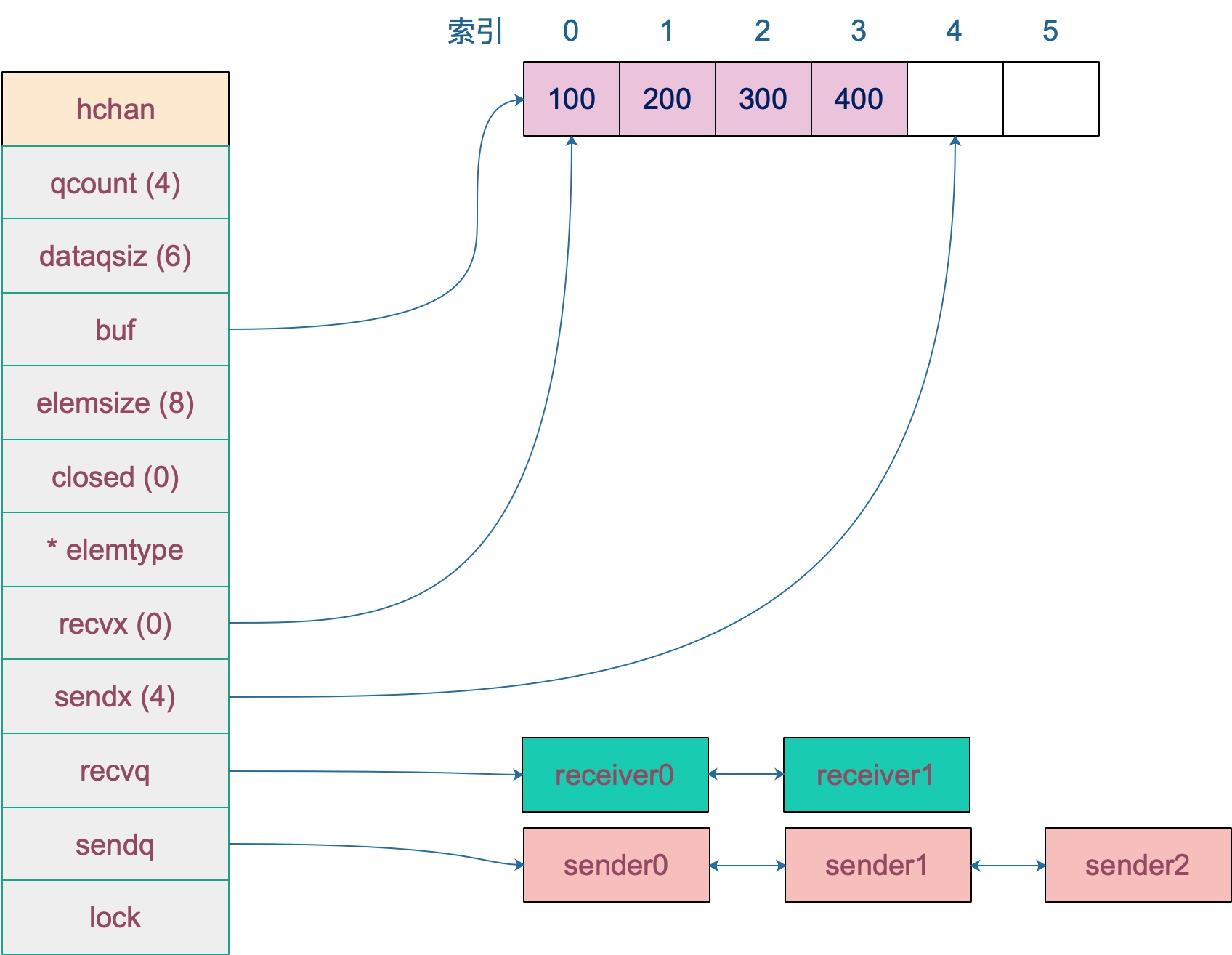
channel的源码实现在src/runtime/chan.go中,底层数据结构解析:
1 | |
其中几个重点字段:
buf:指向底层循环数组,只有缓冲型的channel才会有
sendx、recvx均指向底层循环数组,表示当前可以发送或者可以接受的元素位置索引。
recxq、sendq 分别表示被阻塞的goroutine,这些goroutine由于尝试从channel中读取数据而被阻塞了。
waitq是sudog的一个双向链表,而sudog其实是goroutine的一层封装。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40type waitq struct {
first *sudog
last *sudog
}
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
isSelect bool
// success indicates whether communication over channel c
// succeeded. It is true if the goroutine was awoken because a
// value was delivered over channel c, and false if awoken
// because c was closed.
success bool
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}lock 来保证每个读channel或者写channel都是原子性的
例如创建一个容量为6,元素为int类型的channel数据结构如下:
channel发送和接收元素的本质是什么
channel发送和接受元素的本质都是值拷贝。无论是从 sender goroutine 的栈到 chan buf,还是从 chan buf 到 receiver goroutine,或者是直接从 sender goroutine 到 receiver goroutine。很好的诠释了csp理论,只通过通信来共享内存。
channel 发送数据的过程
带有缓冲的channel,buf是一个循环连表。
当channel 没有满的时候发送数据
- 第一:加锁
- 第二:把数据从goroutine中copy到buf中
- 第三:释放锁。
当channel 中数据已经满了或者channel是一个没有缓存的channel
go的goroutine是一个用户态的线程,用户态的线程是需要用户手动去调度的,go运行时scheduler会帮我们完成调度的事情。
当channel中数据已经满了或者是一个没有缓冲区的channel,那么就会触发goroutine的调度。
比如现在有一个已经满了的channel (ch),现在一个运行中的goroutine G1向channel中send(ch <- 1),这时会主动调用go的调度器,让G1等待,并让出其M,让给其他G使用。同时G1也会被抽象成一个含有G1指针和send元素的sudog的结构体保存到hchan中的sendq队列中,等待被唤醒。
那么G1什么时候会被唤醒呢,那么就得等待其他goroutine来消费channel中buf的数据的时候,比如一个goroutine G2这个时候来消费channel (<- ch),G2将buf中的数据取出的时候,channel会将sendq中的G1推出,将G1的数据拷贝到buf中,并且调用go的scheduler唤醒G1,并将G1放到可运行的goroutine队列中,也就是GMP中的P中。
channel接收数据的过程
当channel中有数据的时候
- 第一:加锁
- 第二:把数据从buf中copy到goroutine中
- 第三:释放锁
当channel中没有数据
当一个运行中的goroutine G1从一个没有数据的channel中读取数据时,G1会主动调用go的scheduler,让G1等待,让出M,让其他G使用,G1还会被抽象为一个含有G1指针和recv空元素的sudog结构体保存到recvq中等待被唤醒。
当另一个goroutine G2向channel中发送数据时,正常情况下:G2应该会将channel锁住,将G2的数据copy到buf中,但是,这边go做了一个优化,直接把数据从G2直接copy到了G1的栈中,在唤醒过程中,G1无需再获取channel的锁,然后再从channel中获取数据,减少了内存copy。
channel资源泄露
channel可能会引发goroutine泄露。
泄露的原因是goroutine操作channel后,处于发送或者接收的阻塞状态,而channel处于满或者空的状态,一直得不到改变。同时,垃圾回收机制也不会回收此类资源,进而导致goroutine会一直在等待队列中。
另外,程序运行过程中,对于一个 channel,如果没有任何 goroutine 引用了,gc 会对其进行回收操作,不会引起内存泄漏。
channel应用场景
停止信号
比如说服务的优雅停止。
1 | |
任务定时
与timer结合,一般是实现超时控制,定时执行。
- 超时控制
1
2
3
4
5select {
case <-time.After(100 * time.Millisecond):
case <-s.stopc:
return false
} - 定时执行
1
2
3
4
5
6
7
8
9
10func worker() {
ticker := time.Tick(1 * time.Second)
for {
select {
case <- ticker:
// 执行定时任务
fmt.Println("执行 1s 定时任务")
}
}
}
解耦生产方和消费方
服务启动时,启动 n 个 worker,作为工作协程池,这些协程工作在一个 for {} 无限循环里,从某个 channel 消费工作任务并执行:
控制并发数
有时需要定时执行几百个任务,例如每天定时按城市来执行一些离线计算的任务。但是并发数又不能太高,因为任务执行过程依赖第三方的一些资源,对请求的速率有限制。这时就可以通过 channel 来控制并发数。
1 | |
构建一个缓冲型的 channel,容量为 3。接着遍历任务列表,每个任务启动一个 goroutine 去完成。真正执行任务,访问第三方的动作在 w() 中完成,在执行 w() 之前,先要从 limit 中拿“许可证”,拿到许可证之后,才能执行 w(),并且在执行完任务,要将“许可证”归还。这样就可以控制同时运行的 goroutine 数。
这里,limit <- 1 放在 func 内部而不是外部,原因是:
如果在外层,就是控制系统 goroutine 的数量,可能会阻塞 for 循环,影响业务逻辑。limit 其实和逻辑无关,只是性能调优,放在内层和外层的语义不太一样。
channel关闭是否还可以读取数据
从一个有缓冲的 channel 里读数据,当 channel 被关闭,依然能读出有效值。只有当返回的 ok 为 false 时,读出的数据才是无效的。
1 | |
先创建了一个有缓冲的 channel,向其发送一个元素,然后关闭此 channel。之后两次尝试从 channel 中读取数据,第一次仍然能正常读出值。第二次返回的 ok 为 false,说明 channel 已关闭,且通道里没有数据。
channel happend-before事件
如果事件A与事件B存在 happend-before关系,即a -> b,b完成的结果一定要体现这种关系。
golang的channel,因为是在gorountine中传递,所以happend-before就显得非常必要。channel的happend-before关系如下:
- 第n个send一定happend-before第n个receive finished,无论缓冲型还是非缓冲型。
- 对于容量为m的缓冲型channel,第n个receive一定happend-before第n+m个send finished。
- 对于非缓冲型的channel,第n个receive一定happend-before第n个send finished。(其实这就是第二种情况的特例,m=0的情况)。
- channel close一定happend-before receive得到通知。
关闭channel流程
1 | |
整体流程:
一个channel中,recvq和sendq中保存着阻塞的接受者和发送者。关闭channel后,对于接受者,会收到一个对应类型的零值,对于发送者,会直接panic。
close首先会上一把锁,将该channel锁住,接着将recvq和sendq中goroutine全部连成一个sudog链表,在解锁,然后将链表上的goroutine全部唤醒。
优雅的关闭channel
关于channel,有几个地方很不方便:
- 无法在不改变channel自身状态的情况下,判断一个channel是否已经关闭。
- 关闭一个已经closed 的channel,会导致panic。
- 向一个closed的channel发送数据会导致panic。
关闭channel原则:
不要再receiver侧关闭channel,也不要在多个sender侧关闭channel。
根据receiver和sender的个数,可以分为以下几种情况:
- 一个sender,一个receiver
- 一个sender,N个receiver
- N个sender,一个receiver
- N个sender,M个receiver
针对1、2情况,都可以在sender侧关闭channel。
针对3情况,可以增加一个传递关闭信号的channel,receiver通过信号channel下大关闭指令,sender监听到关闭指令之后,停止发送数据。
1 | |
针对4情况:
和第 3 种情况不同,这里有 M 个 receiver,如果直接还是采取第 3 种解决方案,由 receiver 直接关闭 stopCh 的话,就会重复关闭一个 channel,导致 panic。因此需要增加一个中间人,M 个 receiver 都向它发送关闭 dataCh 的“请求”,中间人收到第一个请求后,就会直接下达关闭 dataCh 的指令(通过关闭 stopCh,这时就不会发生重复关闭的情况,因为 stopCh 的发送方只有中间人一个)。另外,这里的 N 个 sender 也可以向中间人发送关闭 dataCh 的请求。
1 | |
操作channel情况总结
| 操作 | nil channel | closed channel | not nil, not closed channel |
|---|---|---|---|
| close | panic | panic | 正常关闭 |
| 读 <- ch | 阻塞 | 读到对应类型的零值 | 阻塞或者正常读 |
| 写 ch <- | 阻塞 | panic | 阻塞或者正常写 |