kubernetes 流量跟踪
Kubernetes 网络要求
在深入了解数据包如何在 Kubernetes 集群内流动的细节之前,让我们首先明确 Kubernetes 网络的要求。
Kubernetes 网络模型定义了一组基本规则:
- 集群中的一个 pod 应该能够在不使用网络地址转换 (NAT) 的情况下与任何其他 pod 自由通信。
- 在集群节点上运行的任何程序都应该在不使用 NAT 的情况下与同一节点上的任何 pod 进行通信。
- 每个 pod 都有自己的 IP 地址(IP-per-Pod),每个其他 pod 都可以通过同一地址访问它。
这些要求不会将实施限制为单一解决方案。相反,它们以一般术语描述集群网络的属性。为了满足这些限制,您将必须解决以下挑战:
- 您如何确保同一 pod 中的容器表现得就像它们在同一主机上一样?
- pod 能否到达集群中的其他 pod?
- pod 可以到达服务吗?服务负载平衡请求吗?
- Pod 能否接收集群外部的流量?
在本文中,您将重点关注前三点,从 pod 内网络或容器到容器的通信开始。
Linux 网络名称空间如何在 pod 中工作
让我们考虑一个托管应用程序的主容器和另一个与它一起运行的容器。
在此示例中,您有一个带有 Nginx 容器的 pod 和另一个带有 busybox 的 pod:
1 | |
部署后,会发生以下情况:
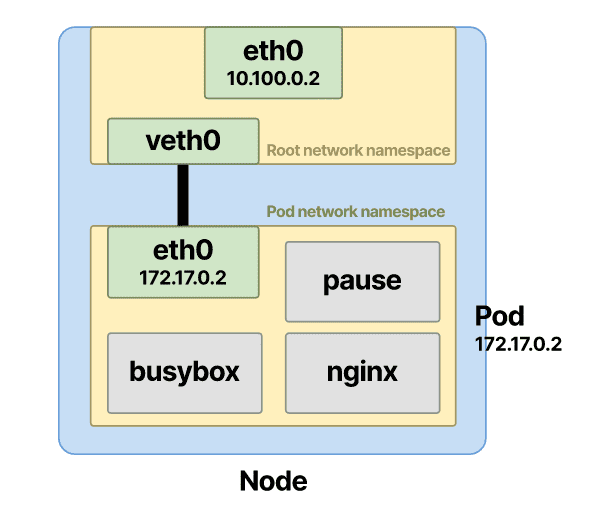
- Pod在节点上获得自己的网络名称空间。
- 一个 IP 地址被分配给 pod,端口在两个容器之间共享。
- 两个容器共享同一个网络命名空间,并且可以在本地主机上看到对方。
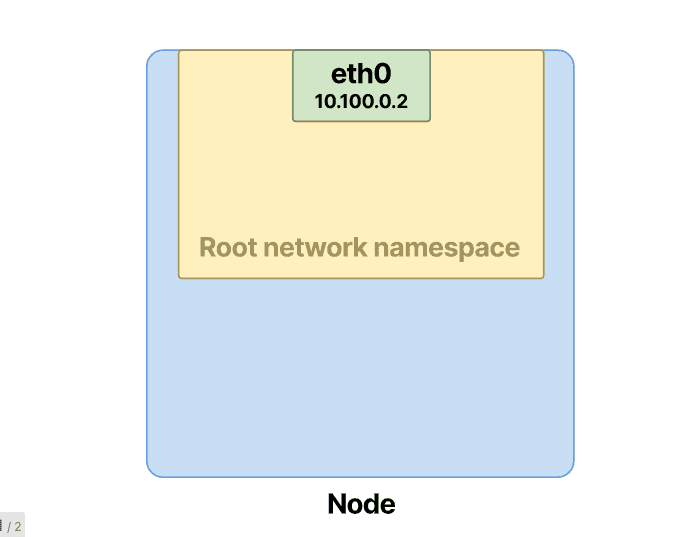
网络配置在后台快速进行。但是,让我们退后一步,尝试理解为什么容器运行需要上述内容。在 Linux 中,网络命名空间是独立的、隔离的、逻辑空间。您可以将网络名称空间视为获取物理网络接口并将其分割成更小的独立部分。每个部分都可以单独配置,并具有自己的网络配置和资源。这些范围包括防火墙规则、接口(虚拟或物理)、路由以及与网络相关的所有其他内容。
物理网络接口拥有根网络命名空间。如下:
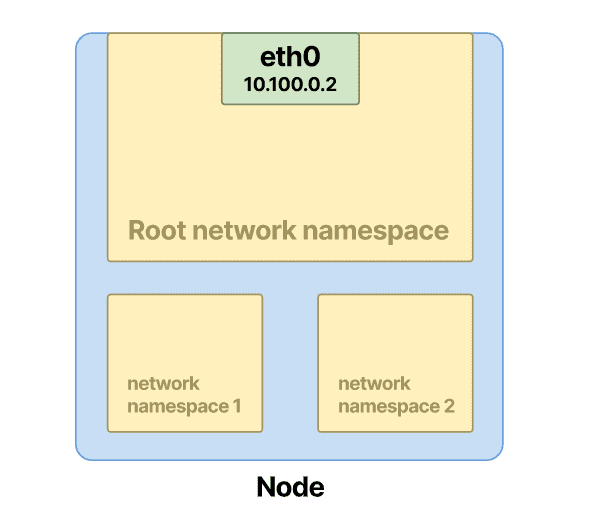
您可以使用 Linux 网络命名空间来创建隔离网络。每个网络都是独立的,除非您将其配置为,否则不会与其他网络通信。如下:
物理接口最终必须处理所有真实数据包,因此所有虚拟接口都是从中创建的。
网络命名空间可以通过ip-netns 管理工具进行管理,您可以使用它ip netns list来列出主机上的命名空间。
请注意,当创建网络名称空间时,它将出现在/var/run/netns下面,但Docker 并不总是遵守这一点。
例如,这些是来自 Kubernetes 节点的命名空间:
1 | |
注意cni-前缀;这意味着命名空间的创建已由 CNI 负责。
当您创建一个 pod,并且该 pod 被分配给一个节点时,CNI将:
- 分配 IP 地址。
- 将容器附加到网络。
如果 pod 包含多个容器,如上,则两个容器都放在同一个命名空间中。
创建 Pod 时,容器运行时首先为容器创建网络命名空间。
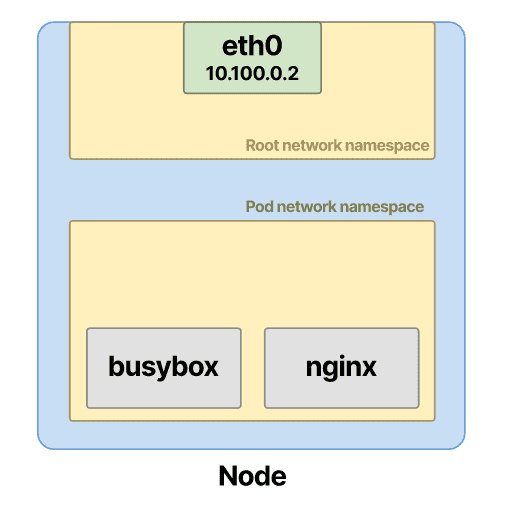
然后,CNI 牵头并为其分配一个 IP 地址。
最后,CNI 将容器附加到网络的其余部分。
那么当您列出节点上的容器时会发生什么?
您可以通过 SSH 连接到 Kubernetes 节点并探索命名空间:
1 | |
lsns 命令可以列出主机上所有可用的命令空间在哪。
请记住,Linux 中有多种命名空间类型。
Nginx 容器在哪里?
pause容器是什么?
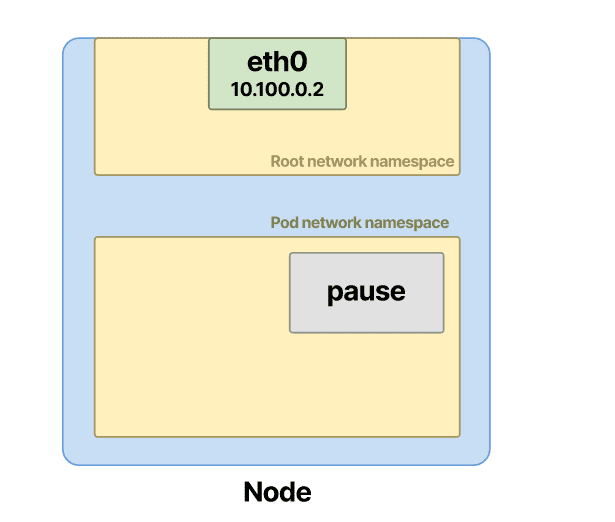
pause 容器在 pod 中创建网络命名空间
让我们列出节点上的所有进程并检查我们是否可以找到 Nginx 容器:
1 | |
该容器列在挂载 ( mnt)、Unix 分时 ( uts) 和 PID ( pid) 命名空间中,但不在网络命名空间 ( net) 中。不幸的是,lsns只显示每个进程的最低 PID,但您可以根据进程 ID 进一步过滤。
您可以使用以下方法检索 Nginx 容器的所有命名空间:
1 | |
又是这个pause进程,这次它劫持了网络命名空间。那是什么?
集群中的每个 pod 都有一个额外的隐藏容器在后台运行,名为pause.
如果列出节点上运行的容器并获取pause容器:
1 | |
您将看到,对于节点上每个分配的 pod,pause容器会自动与其配对。该pause容器负责创建和保存网络命名空间。创建命名空间?是也不是。网络命名空间的创建由底层容器运行时完成。通常是containerd或CRI-O。在部署 pod 和创建容器之前,(除其他外)创建网络名称空间是运行时的责任。
ip netns容器运行时会自动执行此操作,而不是手动运行和创建网络命名空间。
回到pause容器。它包含非常少的代码,并在部署后立即进入休眠状态。然而,它是必不可少的,并且在 Kubernetes 生态系统中起着至关重要的作用。
创建 Pod 时,容器运行时会创建一个带有睡眠容器的网络命名空间。
pod 中的每个其他容器都加入了该容器创建的现有网络命名空间。
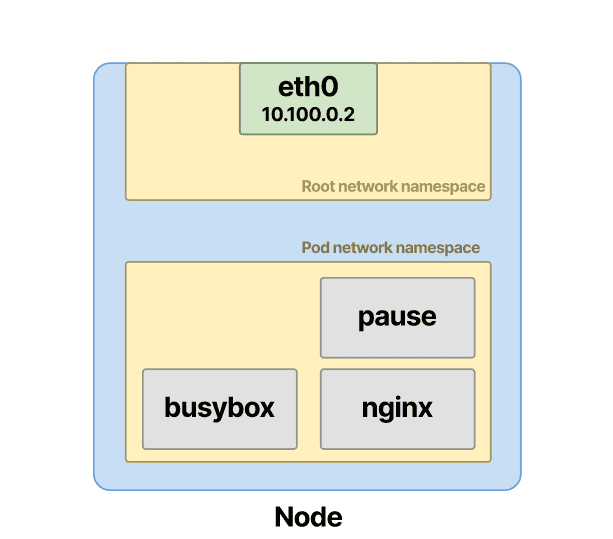
此时,CNI 分配 IP 地址并将容器附加到网络。
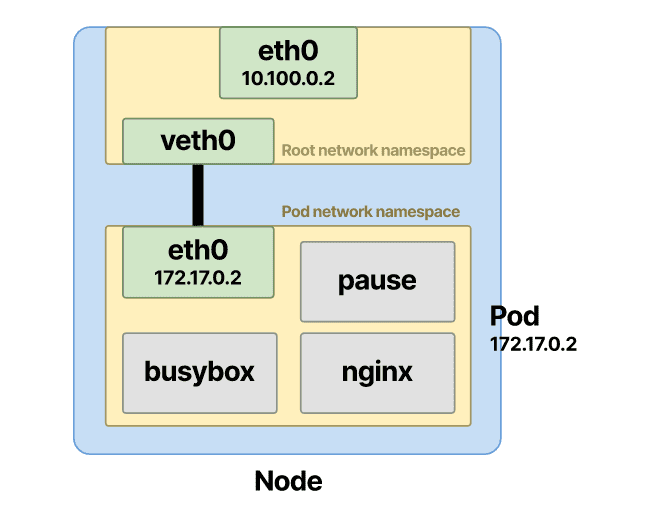
一个进入休眠状态的容器怎么会有用呢?为了理解它的实用性,让我们想象一下有一个像前面的例子一样有两个容器的 pod,但没有pause容器。
一旦容器启动,CNI:
- 使 busybox 容器加入以前的网络命名空间。
- 分配 IP 地址。
- 将容器附加到网络。
如果 Nginx 崩溃了怎么办?CNI 将不得不再次执行所有步骤,并且两个容器的网络都将中断。由于sleep容器不太可能有任何错误,因此创建网络命名空间通常是更安全、更可靠的选择。如果 pod 中的其中一个容器崩溃,其余容器仍然可以响应任何网络请求。
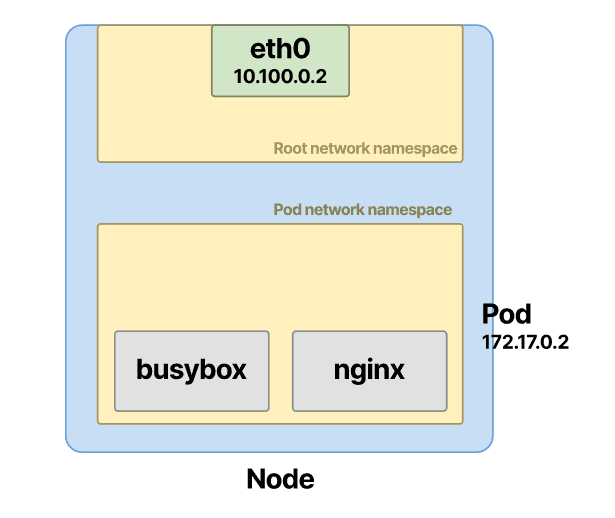
Pod 被分配了一个 IP 地址
我提到 pod 和两个容器接收相同的 IP。那是怎么配置的?在 pod 网络命名空间内,创建了一个接口,并分配了一个 IP 地址。让我们验证一下。
首先,找到 pod 的 IP 地址:
1 | |
接下来,让我们找到相关的网络命名空间。由于网络名称空间是从物理接口创建的,因此您必须访问集群节点。
如果您正在运行minikube,您可以尝试minikube ssh访问该节点。如果您在云提供商中运行,应该有一些方法可以通过 SSH 访问节点。
进入后,让我们找到创建的最新命名网络命名空间:
1 | |
在这种情况下是cni-0f226515-e28b-df13-9f16-dd79456825ac。现在您可以在该命名空间内运行exec命令:
1 | |
那是 pod 的 IP 地址!
让我们通过 grep 找出另一端 @if12:
1 | |
您还可以验证 Nginx 容器是否侦听来自该命名空间内的 HTTP 流量:
1 | |
如果您无法通过 SSH 访问集群中的工作节点,你可以直接用kubectl exec shell 直接进入到busybox容器中执行 ip 和 netstat 命令.
太棒了!
现在我们介绍了容器之间的通信,让我们看看 Pod 到 Pod 的通信是如何建立的。
检查集群中 pod 到 pod 的流量
当 Pod 到 Pod 通信出现问题时,有两种可能的情况:
- Pod 流量的目标是同一节点上的 Pod。
- Pod 流量的目标是驻留在不同节点上的 Pod。
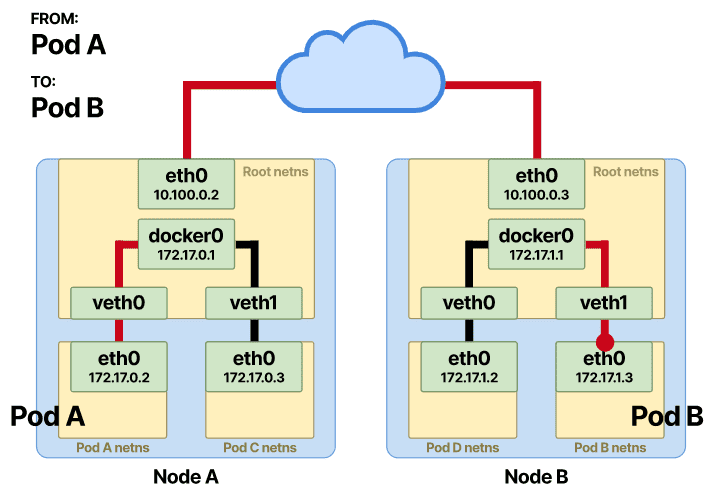
为了使整个设置正常工作,我们需要我们已经讨论过的虚拟接口对和以太网桥。
在继续之前,让我们讨论一下它们的功能以及为什么需要它们。一个 pod 要与其他 pod 通信,它必须首先有权访问节点的根命名空间。这是使用连接两个命名空间的虚拟以太网对实现的:pod 和 root。这些虚拟接口设备(因此是vin veth)连接并充当两个名称空间之间的隧道。使用此veth设备,您可以将一端连接到 pod 的名称空间,将另一端连接到根名称空间。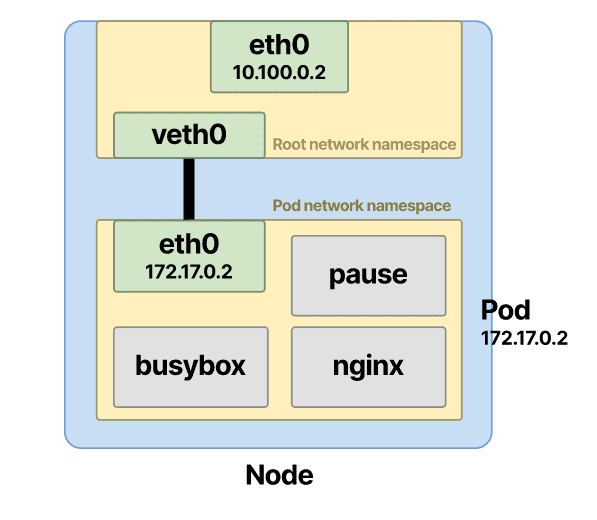
CNI 为您完成此操作,但您也可以手动执行此操作:
1 | |
现在,您的 Pod 的命名空间具有到根命名空间的访问“隧道”。节点上每个新创建的 pod 都将设置一对veth这样的。创建接口对是其中一部分。另一个是为以太网设备分配地址并创建默认路由。veth1让我们探讨如何在 pod 的命名空间中设置接口:
1 | |
在节点端,让我们创建另一veth2对:
1 | |
您可以像以前一样检查现有的veth对。在 pod 的命名空间中,检索接口的后缀eth0。
1 | |
在这种情况下,您可以 通过 grep -A1 ^12 过滤(或只是滚动浏览输出):
1 | |
您也可以使用
ip -n cni-0f226515-e28b-df13-9f16-dd79456825ac link show type veth.
注意两个3: eth0@if12和12: cali97e50e215bd@if3接口上的符号。
从 pod 命名空间,该eth0接口连接到根命名空间中的接口号 12。因此@if12。在该veth对的另一端,根命名空间连接到 pod 命名空间接口编号 3。接下来是连接线对两端的桥veth。
Pod 网络命名空间连接到以太网桥
该网桥会将位于根名称空间中的虚拟接口的每一端“绑定”在一起。该网桥将允许流量在虚拟对之间流动并遍历公共根命名空间。以太网桥位于OSI 网络模型的第 2 层。以太网桥允许您在同一节点上连接多个可用网络。因此你可以使用这种设置并且桥接这两个接口,在同一个节点上,从这个命名空间的pod 的 veth 到另一个 pod 的veth上。
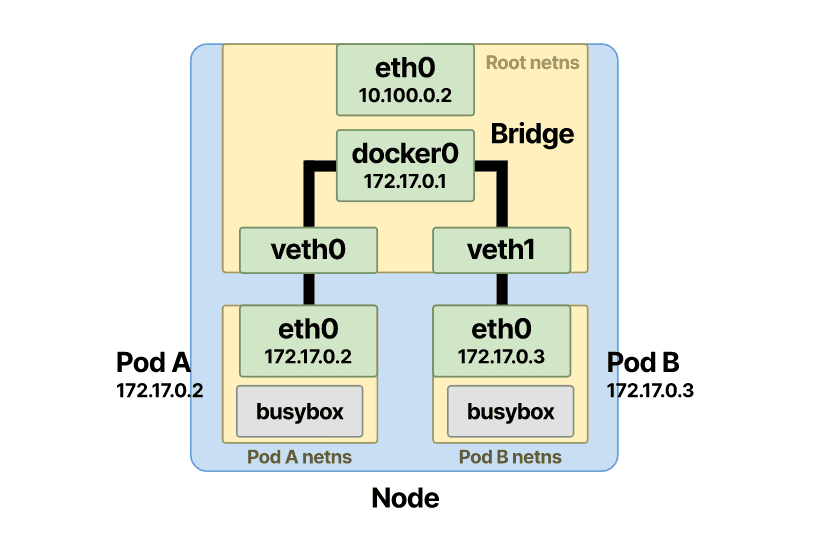
让我们看看实际中的以太网桥和 veth 对。
跟踪同一节点上的 pod 到 pod 流量
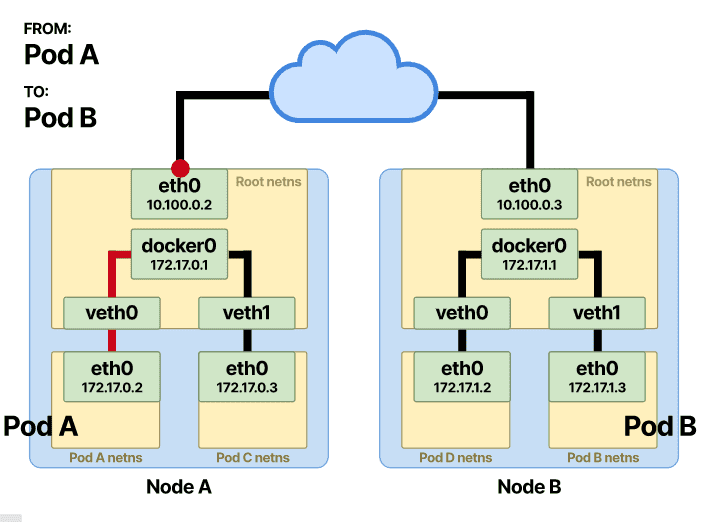
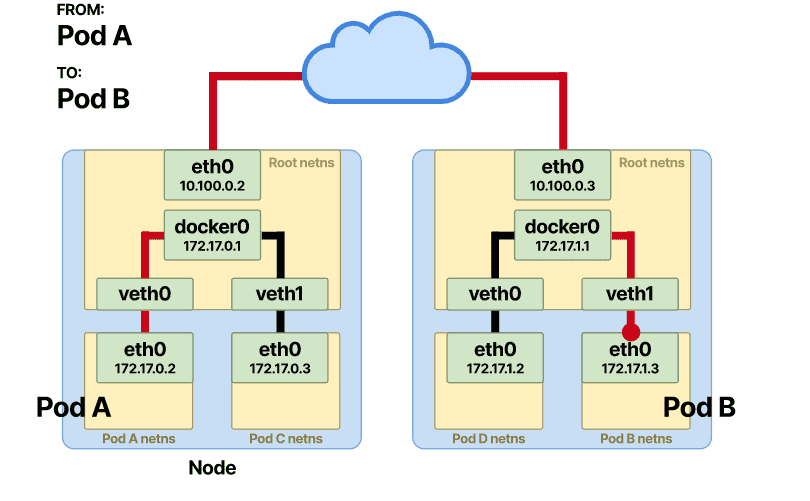
假设同一个节点上有两个 pod,Pod-A 想向 Pod-B 发送消息。
由于目的地不是命名空间中的容器之一,因此 Pod-A 会向其默认eth0接口发送一个数据包。该接口连接到与其绑定的veth接口的一端并用作隧道。这样,数据包就被转发到节点上的根命名空间。
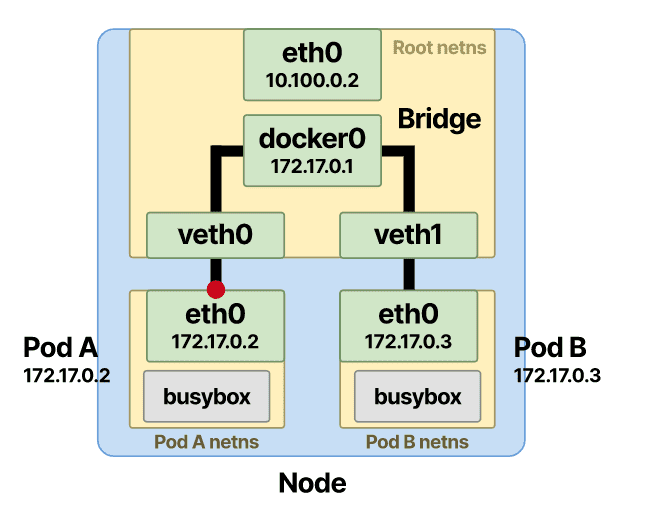
作为虚拟交换机的以太网桥必须以某种方式将目标 pod IP (Pod-B) 解析为其 MAC 地址。
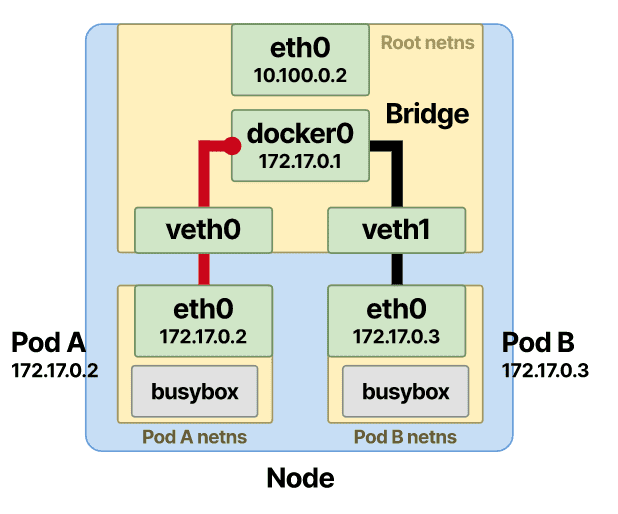
ARP 协议出场了。当帧到达网桥时,将在所有连接的设备上发送 ARP 广播。桥喊谁有 Pod-B IP 地址?
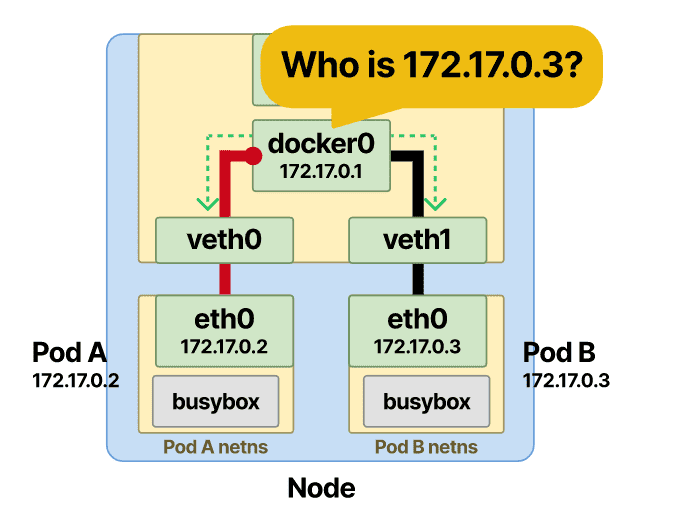
收到连接 Pod-B 接口的 MAC 地址的回复,然后将此信息存储在网桥 ARP 缓存(查找表)中。
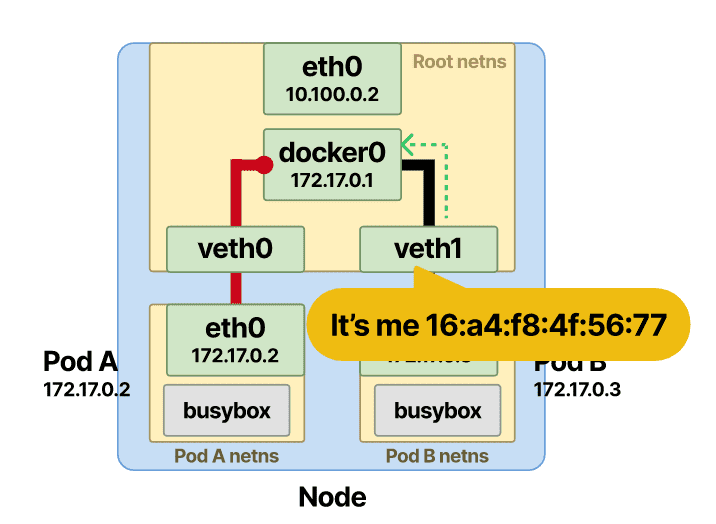
一旦存储了 IP 和 MAC 地址的映射,网桥就会在表中查找并将数据包转发到正确的端点。数据包到达veth根命名空间中的 Pod-B,然后从那里快速到达 Pod-B 命名空间内的eth0接口。
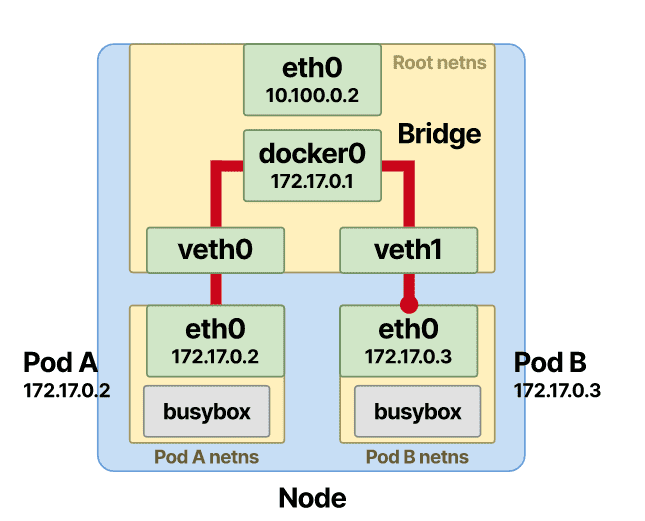
至此,Pod-A 和 Pod-B 之间的通信就成功了。
跟踪不同节点上的 pod 到 pod 的通信
对于需要跨不同节点通信的 pod,通信中需要额外的一跳。
前几个步骤保持不变,直到数据包到达根命名空间并需要发送到 Pod-B。
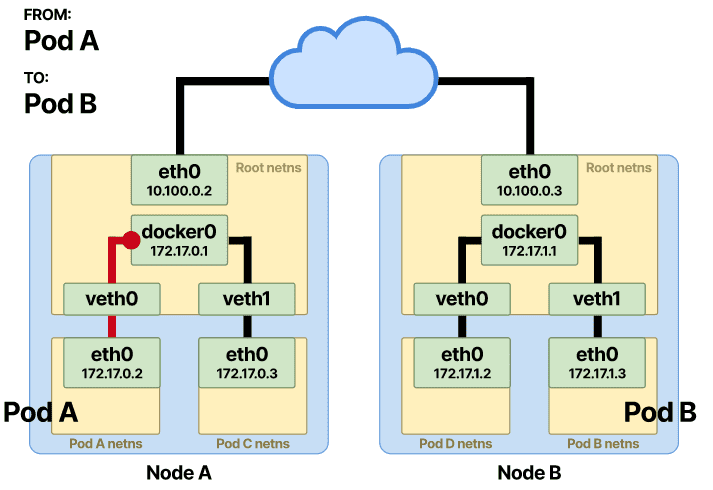
当目标 IP 不在本地网络中时,数据包将转发到该节点的默认网关。节点上的出口或默认网关通常在eth0接口上——将节点连接到网络的物理接口。
这一次,ARP 解析没有发生,因为源 IP 和目标 IP 在不同的网络上。检查是使用按位运算完成的。当目的IP不在当前网络时,转发到节点的默认网关。
按位运算的工作原理
源节点在确定应该将数据包转发到哪里时必须执行按位运算。此操作也称为 ANDing。作为复习,按位与运算产生以下结果:
1 | |
除了1and之外的任何内容1都是false的。如果源节点的 IP 为 192.168.1.1,子网掩码为 /24,而目标 IP 为 172.16.1.1/16,则按位与运算将表明它们确实在不同的网络上。这意味着目标 IP 与数据包的源不在同一网络上,因此数据包将通过默认网关转发。
下面是数学时间。我们必须从二进制的 32 位地址开始进行与操作。让我们首先找出源和目标 IP 网络。
1 | |
对于按位运算,您需要将目标 IP 与数据包来源节点的源子网进行比较。
1 | |
正如我们所见,ANDed 网络的结果是 172.16.1.0,它不等于 192.168.1.0——来自源节点的网络。有了这个,我们确认源 IP 地址和目标 IP 地址不在同一网络上。例如,如果目标 IP 是 192.168.1.2,即与发送 IP 在同一子网中,则 AND 操作将产生节点的本地网络。
1 | |
进行按位比较后,ARP 将检查其查找表以查找默认网关的 MAC 地址。如果有条目,它将立即转发数据包。否则,它将首先进行广播以确定网关的MAC地址。
数据包现在被路由到另一个节点的默认接口。我们称它为 Node-B。
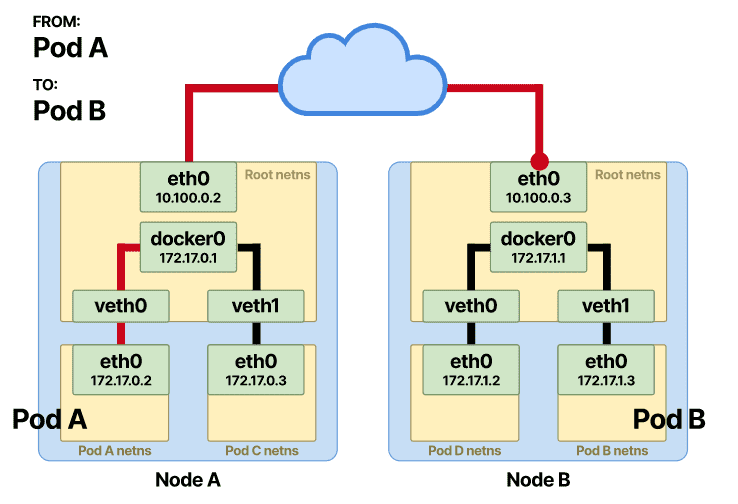
以相反的顺序。数据包现在位于 Node-B 的根命名空间并到达网桥,另一个 ARP 解析将在网桥上进行。
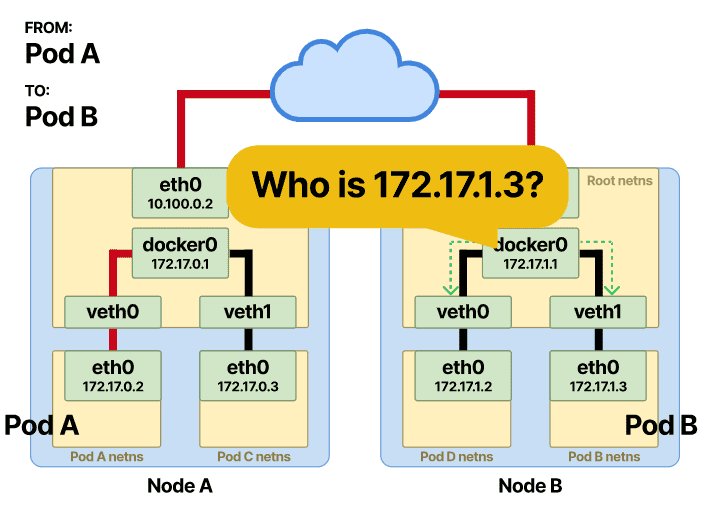
收到一个回复,其中包含连接 Pod-B 的接口的 MAC 地址。
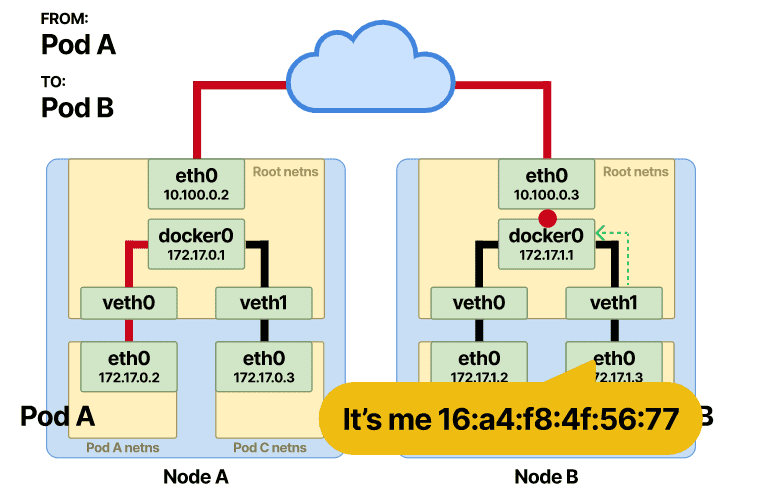
这次网桥通过 Pod-B veth 设备转发帧,它到达自己命名空间中的 Pod-B。
现在您已经熟悉了 pod 之间的流量如何流动,让我们花时间探索 CNI 如何创建上述内容。
容器网络接口 - CNI
容器网络接口(CNI)关注当前节点中的网络。
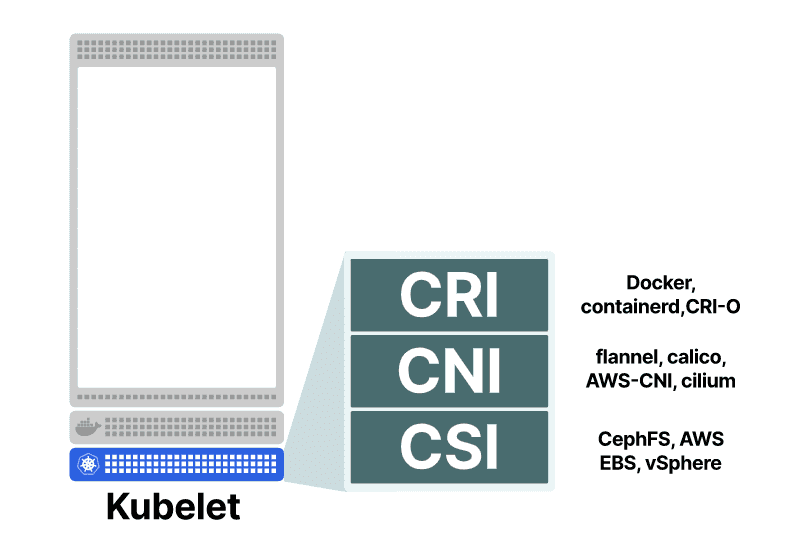
您可以将 CNI 视为一组规则,网络插件应遵循这些规则来解决某些Kubernetes 网络要求。然而, Kubernetes 并没有与特定的网络插件相绑定。你可以使用一下任意的一款网络插件:
- Calico
- Cillium
- Flannel
- Weave Net
- 或者其他的网络插件.
它们都执行相同的 CNI 标准。如果没有 CNI,您将需要手动:
- 创建接口。
- 创建 veth 对。
- 设置命名空间网络。
- 设置静态路由。
- 配置以太网桥。
- 分配 IP 地址。
- 创建 NAT 规则。
还有许多其他需要过多手工操作的事情。当需要删除或重新启动 pod 时,更不用说删除或调整上述所有内容了。
CNI 必须支持四种不同的操作:
- ADD - 将容器添加到网络。
- DEL - 从网络中删除容器。
- CHECK - 如果容器的网络有问题则返回一个错误。
- VERSION - 显示插件的版本。
让我们看看它在实践中是如何工作的。
当一个 pod 被分配到一个特定的节点时,kubelet 本身不会初始化网络。相反,他将这个任务扔给了CNI。CNI通过指定的json配置文件开始工作。你可以在节点的/etc/cni/net.d查看该json文件:
1 | |
每个 CNI 插件使用不同类型的网络设置配置。例如,Calico 使用与 BGP 路由协议配对的第 3 层网络来连接 pod。Cilium 在第 3 层到第 7 层使用 eBPF 配置覆盖网络。与 Calico 一样,Cilium 支持设置网络策略来限制流量。
那么你应该使用哪一个?需要看情况而定。
目前有两类CNI:
第一类:您可以找到使用基本网络设置(也称为平面网络)的 CNI,并从集群的 IP 池中为 pod 分配 IP 地址。这可能会成为一种负担,因为您可能会很快耗尽所有可用的 IP 地址。
第二类:是使用覆盖网络,简单来说,覆盖网络是主(底层)网络之上的辅助网络。覆盖网络的工作原理是封装来自底层网络的任何数据包,这些数据包的目的地是另一个节点上的 pod。覆盖网络的一种流行技术是VXLAN,它可以通过 L3 网络隧道传输 L2 域。
那么哪个更好呢?没有单一的答案,通常取决于您的要求。
如果你正在搭建一个成千上万个节点的大集群,也许覆盖网络更适合你。
您如果看重更简单的设置和检查网络流量而不会在嵌套网络中丢失的能力,扁平网络非常适合您。网络更适合你。
现在我们已经讨论了 CNI,让我们来探索 Pod 到服务的通信是如何工作的。
探索 Pod 到 Service 的流量
由于 Kubernetes 环境中 pod 的动态特性,分配给它们的 IP 地址不是静态的。它们是短暂的,每次创建或删除 pod 时都会发生变化。Service解决了这个问题,并提供了一种稳定的机制来连接到一组 pod。
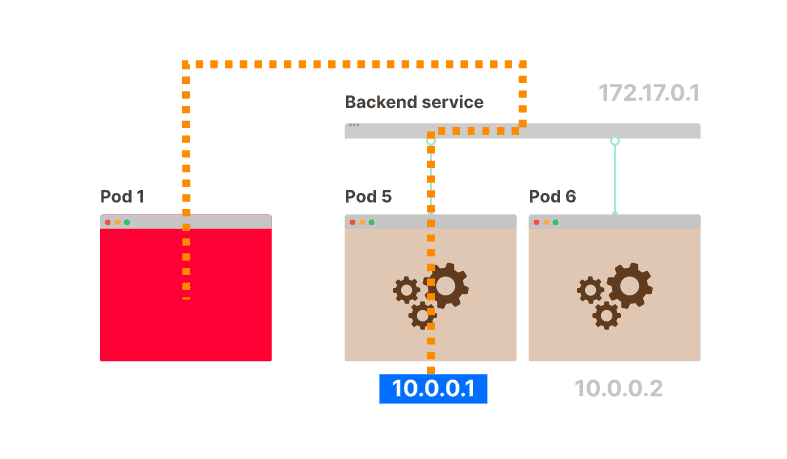
默认情况下,当您在 Kubernetes 中创建服务时,会创建一个虚拟 IP 并分配给它。同时,你可以用选择器将一组pod关联到service。
当一个 pod 被删除并添加一个新的 pod 时会发生什么?服务的虚拟 IP 保持静态不变。并且流量会打到新的pod,且无需人工干预!换句话说,Kubernetes 中的服务类似于负载均衡器。
但它们是如何工作的?
使用 Netfilter 和 Iptables 拦截和重写流量
Kubernetes 中的 service 建立在两个 Linux 内核组件之上:
- Netfilter
- iptables.
Netfilter 是一个允许配置数据包过滤、创建 NAT 或端口转换规则以及管理网络中的流量的框架。此外,它还屏蔽和防止未经允许的连接到达服务。iptables是实现不同Netfilter功能的模块。您使用 iptables CLI 动态更改过滤规则并将它们插入 netfilters 挂钩点。过滤器组织在不同的表中,其中包含用于处理网络流量数据包的链。每个协议使用不同的内核模块和程序。
当提到 iptables 时,它通常表示用于 IPv4。对于 IPv6 规则,CLI 称为 ip6tables。
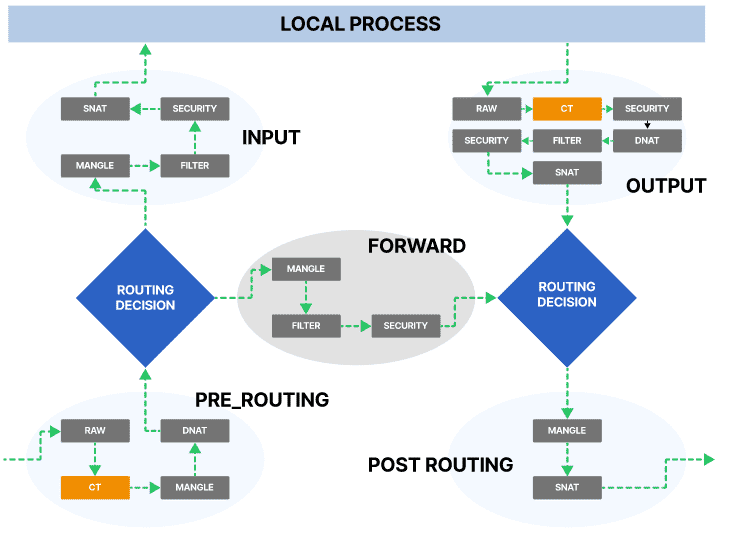
Iptables有五种链,每一种链都直接映射到Netfilter的钩子上。从 iptables 的角度来看,它们是:
- PRE_ROUTING
- INPUT
- FORWARD
- OUTPUT
- POST_ROUTING
它们相应地映射到 Netfilter 挂钩:
- NF_IP_PRE_ROUTING
- NF_IP_LOCAL_IN
- NF_IP_FORWARD
- NF_IP_LOCAL_OUT
- NF_IP_POST_ROUTING
当数据包到达时,根据它所处的阶段,它将“触发”一个 Netfilter 挂钩,该挂钩应用特定的 iptables 过滤。
哎呀!看起来很复杂!不过没什么好担心的。这就是我们使用 Kubernetes 的原因,以上所有内容都是通过使用Service抽象出来的,一个简单的 YAML 定义会自动设置这些规则。如果你有兴趣查看 iptables 规则,你可以连接到一个节点并运行:
1 | |
您还可以使用iptable_vis工具可视化节点上的 iptables 链。
想象一下手动配置这些数百万的规则!
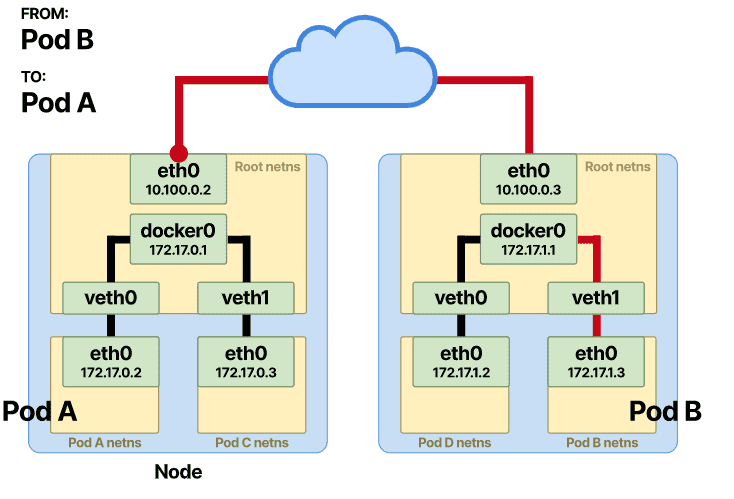
我们已经解释了当 pod 在相同和不同的节点上时 Pod 到 Pod 的通信是如何发生的。在 Pod-to-Service 中,通信的前半部分保持不变。
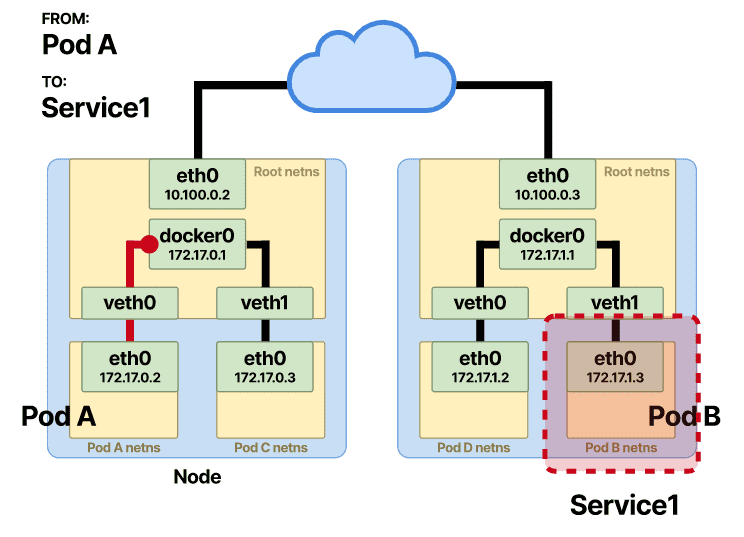
当请求从 Pod-A 开始,并且它想要到达 Pod-B 时,在这种情况下,Pod-B 将在 Service “后面”,在传输的中途会发生额外的变化。请求通过Pod-A 命名空间中的 eth0 接口发起,并通过veth对并到达根名称空间的以太网桥,一旦到达网桥,数据包就会立即通过默认网关转发。在 Pod-to-Pod 部分,主机进行按位比较,因为 Service 的 vIP 不是节点 CIDR 的一部分,数据包将立即通过默认网关转发。如果查找表中没有找到对应的MAC地址,则会通过ARP协议去查找。
奇迹发生了!
就在该数据包通过节点的路由过程之前,NF_IP_PRE_ROUTING触发了 Netfilter 挂钩,并应用了 iptables 规则。该规则进行 DNAT 更改并重写 Pod A 数据包的目标 IP。
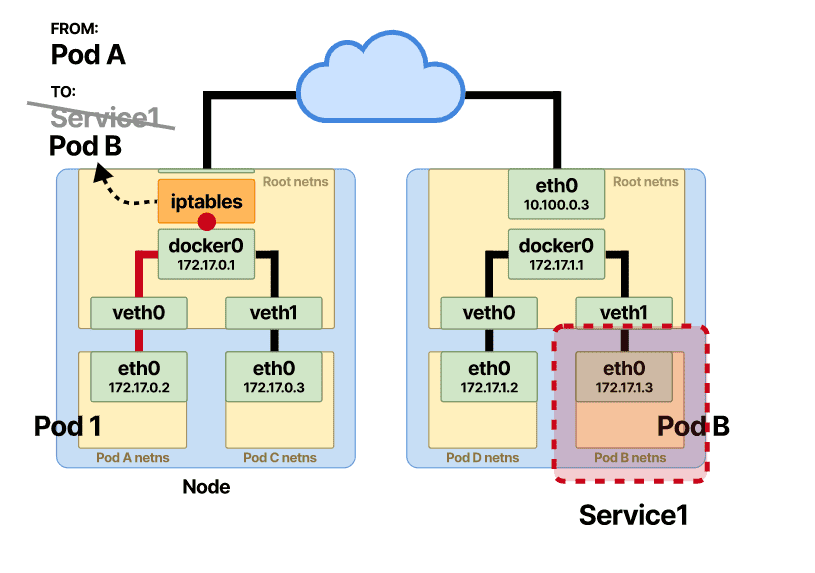
之前的服务 vIP 目的地被重写为 Pod 的 B IP 地址。从那里开始,路由与 Pod 到 Pod 直接通信 一样。
然而,在所有这些通信之间,使用了另一个第三个特征。此功能称为 conntrack或连接跟踪。Conntrack 会将数据包与连接相关联,并在 Pod-B 发回响应时跟踪其来源。NAT 严重依赖 conntrack 来工作。如果没有连接跟踪,它就不知道将包含响应的数据包发回何处。当使用 conntrack 时,数据包的返回路径很容易设置为具有相同的源或目标 NAT 更改。另一半现在的顺序相反。Pod-B 接收并处理了请求,现在将数据发送回 Pod-A。
现在发生了什么?
检查来自服务的响应
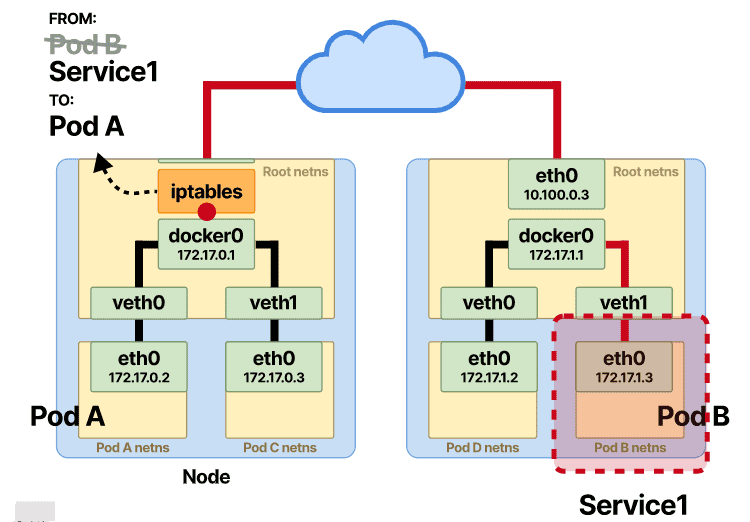
现在 Pod-B 发送响应,将其 IP 地址设置为源,将 Pod 的 A IP 地址设置为目标。
当数据包到达 Pod-A 所在节点的接口时,会发生另一个 NAT。
这次使用conntrack,源IP地址发生变化,iptables规则做了一次SNAT,把Pod的B源IP换成了原来服务的vIP。
对于 Pod-A,这看起来好像传入响应源自服务而不是 Pod-B。
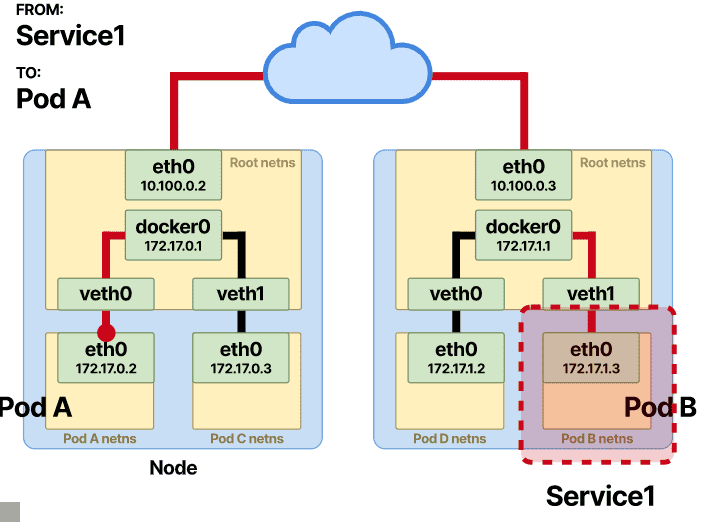
其余相同;一旦 SNAT 完成,数据包就会到达根命名空间中的以太网桥,并通过 veth 对转发到 Pod-A。